이 패턴은
가상 머신 명령어를 인코딩한 데이터로 행동을 표현할 수 있게 해준다.
?? 뭐라는거야 ??
알아보자
게임 개발이 재밌을 수는 있다.
나도 그렇게 느낀다. 그렇다고 해서 쉽진 않다.
게임은 모든 기술의 집약체이기 때문이다.
네트워크가 발전해서 실시간 게임이 나왔고
램이 늘어나서 방대한 게임이 나왔고, CPU가 발전해서 실제와 같은 물리현상을 적용한 게임이 나왔고
GPU가 발전해서 실제와 구분이 안가는 그래픽을 보여주는 게임이 나오는 등..
모든 기술의 발전이 게임과 연관되어있다.
그만큼 게임은 엄청나게 볼륨이 커졌고 재미있어도 쉽지는 않게 되었다.
또한 모든 플랫폼을 넘나들 수 있게 만들어야.. 수익도 유저도 많이 확보할 수 있다.
또한 플랫폼이 바뀌더라도 게임의 품질이 어느정도 보장되어야 한다.
게임 언어는 성능과 안정성을 위해서 C++과 같은 중량 언어, heavy weight language를 사용한다.
이런 언어는 하드웨어 성능을 최대한 이끌어낼 수 있는 저수준 표현 + 풍부한 타입시스템을 제공한다.
더군다나 숙달된 프로그래머가 되기 위해서는 몇 년간 집중 훈련을 받아야 하고, 그런 후에도 엄청난 규모의 코드를 이겨내야 한다.
규모가 큰 게임이라는 것은
빌드하는데에만 커피 한 잔의 시간이 걸린다.
**커피 한 잔이란 원두를 고르는 것부터 로스팅, 그라인드, 내려서 라떼 아트로 먹기까지를 말하는 것이다.
바이트 코드에 대해서 알기 전에
한 이야기를 들어보자
두 마법사가 서로를 죽일 때까지 싸우기로 했다.
마법을 코드로 만들어도 되지만 이러면 마법을 수정이 필요할 때마다 코드도 같이 고쳐야 한다.
기획자가 수치를 약간 바꿔서 느낌만 보고 싶을 때에도 게임 전체를 빌드해서 다시 실행해야 한다.
?? 앞서 말했듯이 게임의 빌드는 긴 과정이다.
즉, 요즘 게임처럼 출시한 뒤에도 수시로 업데이트를 통해 버그를 고치거나 컨텐츠를 추가할 때
용이해야 한다는 말인데.. 다 하드 코딩이 되어있다면 수정할 때마다 게임 실행 파일을 패치해야 한다.
더 나아가 모드, mod를 지원한다면 (유저 커스터마이징과 비슷) 자신만의 마법을 만들고 싶은 유저들에게
마법을 만들 수 있게 한다면 코드로 마법을 구현했을 때 모드 개발자는 게임을 빌드하기 위해서 컴파일러 툴체인을 다 갖추어야 하고 개발사는 소스를 공개해야 한다.
이렇게 만든 마법에 버그라도 있으면 전체 게임에 문제가 생긴다.
게임 엔진에서 사용하는 개발 언어는 마법을 구현하기에는 적합하지 않다.
마법 기능을 핵심 게임 코드와 안전하게 격리할 방법이 필요하다.
쉽게 고칠 수 있고, 쉽게 불러올 수 있고 나머지 게임들과는 분리해서 관리하고 싶다.
저자는 "데이터"가 이렇다고 생각한다.
행동을 "데이터 파일"에 따로 정의해놓고 게임 코드에서 읽어서 "실행"하는 것이다.
여기서 "데이터"란 파일에 있는 바이트를 말하는 것이다.
바이트로 행동을 어떻게 표현할 수 있을까??
이제 알아보자
인터프리터 패턴
??파이썬??
맞다. 인터프리터는 그것이다.
간략한 수식을 써보겠다.
(1+2) * (3-4)
이런 표현식을 읽어서 언어 문법에 따라 각각 객체로 변환해야 한다.
숫자 리터럴은 아래 같이 객체가 된다.

숫자 상수는 단순히 숫자 값을 래핑한 객체다.
연산자도 객체로 바뀌는데, 이때 피연산자도 같이 참조한다.
괄호와 우선순위까지 고려하게 되면 이렇게 객체 트리가 된다.

인터프리터 패턴의 목적은 이런 추상 구문 트리를 만드는 것뿐만 아니라
이를 실행하는 데에 있다.
표현식 혹은 하위표현식 객체로 트리를 만든 후에
진짜 객체지향 방식으로 표현식이 자기 자신을 평가하게 한다.
먼저 모든 표현식 개체가 상속받을 상위 인터페이스를 만든다.
class Expression
{
public:
virtual ~Expression() {}
virtual double evaluate() = 0;
};
언어 문법에서 지원하는 모든 표현식마다 Expression 인터페이스를 상속받는 클래스를 정의한다.
숫자는 아래와 같다.
class NumberExpression : public Expression
{
public:
NumberExpression(double value)
: value_(value)
{}
virtual double evaluate()
{
return value_;
}
private:
double value_;
};
숫자 리터럴 표현식은 단순히 자기 값을 평가한다.
덧셈, 곱셈에는 하위 표현식이 있기 때문에 더 복잡하다.
하위 표현식이 있다면 자기를 평가하기 전에 먼저 하위부터 평가를 재귀적으로 한다.
class AdditionExpression : public Expression
{
public:
AdditionExpression(Expression* left, Expression* right)
: left_(left),
right_(right)
{}
virtual double evaluate()
{
// Evaluate the operands.
double left = left_->evaluate();
double right = right_->evaluate();
// Add them.
return left + right;
}
private:
Expression* left_;
Expression* right_;
};
간단한 클래스 몇 개만으로 어떤 복잡한 수식 표현도 마음껏 나타내고 평가할 수 있다.
필요한 만큼 객체를 더 만들어 원하는 곳에 적절히 연결하기만 하면 된다.
인터프리터 패턴은 아름답기만 해보이지만
문제가 조금 있다.
크게 3가지다.
-코드를 로딩하면서 작은 객체를 엄청 많이 만들고 연결한다.
-이들 객체와 객체를 잇는 포인터는 많은 메모리를 소모한다.
-포인터를 따라서 하위표현식에 접근하기 때문에 데이터 캐시에 치명적이다.
??? 아니 그게 뭔데???
결국 느리단 말이다.
느린데다 메모리도 엄청 쓴다.
그래서 게임 분야에선 인터프리터를 쓰는 언어를 채택하지 않는다.
그렇다면 가상 기계어, Virtual Machine Language는 뭐길래.. 좋다는 걸까?
일반적인 게임을 생각해보자.
게임이 실행될 때 플레이어의 컴퓨터가 C++ 문법 트리구조를 런타임에 순회하진 않는다.
대신 미리 컴파일해놓은 기계어를 바로 실행한다.
그렇다면 기계어의 장점은 무엇일까?
-바이너리 데이터가 연속적으로 꽉 차있으니 한비트도 낭비하지 않고 밀도 높은 데이터다.
-명령어가 같이 모여있고 순차적으로 실행된다. 실행이 선형적이다.
-각 명령어는 최소작업들로 구성되어있다. 조합으로 여러 행동을 만드는 것이다. 로우 레벨이다.
-최소 작업들로 구성되어있고 선형적이고 밀도가 높아 빠르고 메모리 효율이 높다.
이런 장점이 좋다해도.. 누가 0101000111으로 구현하겠는가..?
그래서 우리는 기계어의 성능 + 인터프리터의 편리함의 중간을 추구해보려고 한다.
실제 기계어를 읽어서 바로 실행하는 대신
우리가 알아듣는 가상 기계어를 만들면 어떨까?
가상기계어를 실행하는 에뮬레이터도 만들면 괜찮을 것 같다.
그래서 만들어진 것이
VM, Virtual Machine 가상머신이고 가상 바이너리 기계어는 바로 바이트 코드가 되었다.
바이트 코드는 유연하고, 데이터로 여러 가지를 쉽게 정의할 수 있으며 인터프리터 패턴보다 성능이 좋다.
배워놓으면
바이트 코드를 직접 구현할 일은 없어도 바이트 코드로 구현된 언어를 이해하기는 쉬워질 것이다.
명령어 집합은 실행할 수 있는 저수준, low-level의 작업을 정의한다.
명령어는 일련의 바이트로 인코딩된다.
가상 머신은 중간 값들을 스택에 저장해가면서 이들 명령어를 하나씩 실행한다.
명령어를 조합함으로써 복잡한 고수준의 행동을 정의하는 것이다.
그렇다면 바이트 코드는 도대체 언제 쓸까??
바이트코드 패턴은 어쩌면 가장 복잡하며 적용하기 어렵다.
정의할 행동은 많은데 게임 구현에 사용된 프로그래밍 언어로는 구현하기는 어려울 때 사용한다.
그러한 경우를 생각해보면
-언어가 저수준이라 손이 너무 많이 가거나
-컴파일 시간이나 다른 빌드 환경 때문에 반복 개발하기 어렵거나
-보안에 취약하고 나머지 코드로부터 격리해야해서
어려움을 느낄 때 바이트코드 패턴을 쓴다.
근데 대부분의 게임이 위 조건 중에 하나는 있을 것이다.
모두가 빠른 반복 개발과 안전성을 원한다. 거저 얻어지는 것이 아닐 뿐이다.
바이트코드는 네이티브 코드보다는 느리므로 성능이 민감한 곳에서는 쓰이지 않는다.
앞에 대한 바이트코드에 대한 설명을 실제 예제로 알아보자.
예제를 보다보면 구현이 쉽다고 느낄 수 있다.
먼저 VM에 필요한 명령어 집합을 정의하자.
API와 같은 것이라고 보면 편하다.
앞서 나온 마법에 대해서 C++로 구현을 하려면 어떤 API가 필요할까?
대개 마법은 마법사의 상태를 변화시킨다.
void setHealth(int wizard, int amount);
void setWisdom(int wizard, int amount);
void setAgility(int wizard, int amount);wizard는 마법을 적용할 대상이다.
amount는 그 정도를 뜻한다.
여기다 사운드와 파티클 효과를 추가하자.
void playSound(int soundId);
void spawnParticles(int particleType);
뭐 추가할 다른 것들도 있겠지만 일단 이정도로 시작해보자
이들 API가 데이터에서 제어 가능한 뭔가로 어떻게 바뀌는지 생각해보자
우선 매개변수부터 전부 제거한다.
set____() 같은 함수들은 마법사의 스탯을 항상 최댓값으로 만든다.
이펙트 효과 역시 하드코딩된 한 줄짜리 사운드와 파티클 이펙트다.
이제 마법은 단순한 명령어의 집합이 된다.
각 명령어는 작업이 되고 이들이 모여 마법을 부린다.
해당 명령어들은 enum으로, 열거형으로 표현가능하다.
enum Instruction
{
INST_SET_HEALTH = 0x00,
INST_SET_WISDOM = 0x01,
INST_SET_AGILITY = 0x02,
INST_PLAY_SOUND = 0x03,
INST_SPAWN_PARTICLES = 0x04
};
마법을 데이터로 인코딩하려면 이들 열거형 값을 배열에 저장하면 된다.
이러한 명령어가 별로 없다보니 1바이트 안에 전체 열거형 값을 다 표현할 수 있다.
마법을 만들기 위한 코드가 실제로는 바이트들의 목록이 되는 것이다.
이제서야 "바이트코드"가 왜 그렇게 불리는지 알 수 있다.
명령 하나를 실행하기 위해서는 어떤 원시(primitive) 명령인지 보고 이에 맞는 메서드를 호출한다.
switch (instruction)
{
case INST_SET_HEALTH:
setHealth(0, 100);
break;
case INST_SET_WISDOM:
setWisdom(0, 100);
break;
case INST_SET_AGILITY:
setAgility(0, 100);
break;
case INST_PLAY_SOUND:
playSound(SOUND_BANG);
break;
case INST_SPAWN_PARTICLES:
spawnParticles(PARTICLE_FLAME);
break;
}
이런 식으로 인터프리터는 코드와 데이터를 연결한다.
마법 전체를 실행하는 VM 에서는 이 코드를 아래와 같이 래핑(wrapping)한다.
class VM
{
public:
void interpret(char bytecode[], int size)
{
for (int i = 0; i < size; i++)
{
char instruction = bytecode[i];
switch (instruction)
{
// Cases for each instruction...
}
}
}
};**바이트코드가 들어있는 배열에서 값을 빼내와서 해당 바이트코드에 맞는 instruction을 수행하게끔 한다.
위와 같이 구현하면 간단한 VM 구현이고
하지만 위에 대해서는 그냥 명령어를 바이트코드로 불러온다 뿐이지..
이것으로 살짝 바꿔서 다른 것을 만들 수 있다고 생각되지는 않는다.
바이트코드가 실제로 의미가 생기려면 매개변수를 받을 수 있어야 한다.
복잡한 중첩식을 실행하려면 가장 안쪽 하위 표현식부터 계산해서
그 결과를 담고 있는 표현식의 인수로 넘기고..
이를 전체 표현식이 다 계산될 때까지 반복하면 된다.
인터프리터 패턴에서는 중첩 객체 트리 형태로 중첩식을 직접 표현했다.
속도를 높이기 위해 명령어를 1차원으로 나열해도
하위표현식 결과를 중첩 순서에 맞게 다음 표현식에 전달해야 한다.
때문에 CPU처럼 스택을 이용해서 명령어 실행 순서를 제어한다.
class VM
{
public:
VM()
: stackSize_(0)
{}
// Other stuff...
private:
static const int MAX_STACK = 128;
int stackSize_;
int stack_[MAX_STACK];
};
VM 클래스에는 값 스택이 들어 있다.
예제 코드에서는 명령어가 숫자 값만 받을 수 있기 때문에 그냥 int 배열로 만들었다.
명령어들은 이 스택을 통해서 데이터를 주고 받는다.
이름에 맞게 스택에 값을 넣고 뺄 수 있도록 두 메서드를 추가해보자.
class VM
{
private:
void push(int value)
{
// Check for stack overflow.
assert(stackSize_ < MAX_STACK);
stack_[stackSize_++] = value;
}
int pop()
{
// Make sure the stack isn't empty.
assert(stackSize_ > 0);
return stack_[--stackSize_];
}
// Other stuff...
};
명령어가 매개변수를 받을 때는 다음과 같이 스택에서 꺼내온다.
switch (instruction)
{
case INST_SET_HEALTH:
{
int amount = pop();
int wizard = pop();
setHealth(wizard, amount);
break;
}
case INST_SET_WISDOM:
case INST_SET_AGILITY:
// Same as above...
case INST_PLAY_SOUND:
playSound(pop());
break;
case INST_SPAWN_PARTICLES:
spawnParticles(pop());
break;
}스택에서 값을 얻어오려면 리터럴 명령어가 필요하다.
리터럴 명령어는 정수 값을 나타낸다.
하지만 리터럴 명령어는 자신의 값을 어디에서 얻어오는 것일까?
명령어 목록이 바이트의 나열이라는 점을 활용해서 숫자를 바이트 배열에 직접 집어넣으면 된다.
숫자 리터럴을 위한 명령어 타입은 다음과 같이 정의한다.
case INST_LITERAL:
{
// Read the next byte from the bytecode.
int value = bytecode[++i];
push(value);
break;
}
바이트코드 스트림에서 옆에 있는 바이트를 숫자로 읽어서 스택에 집어넣는 것이다.
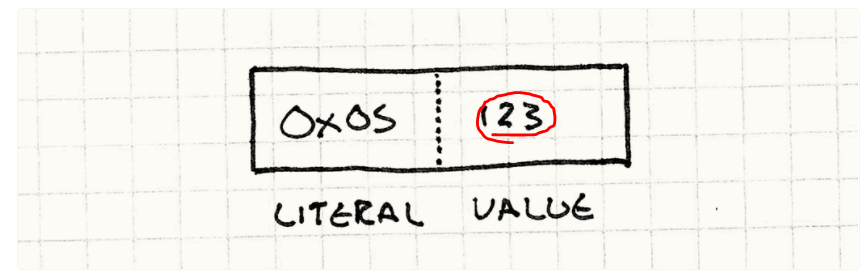
인터프리터가 명령어 몇 개를 실행하는 과정을 보면서 스택 작동 원리를 이해해보자.
먼저 스택이 비어있는 상태에서 인터프리터가 첫 번째 명령을 실행한다.

먼저 INST_LITERAL 부터 실행한다.
이 명령은 자신의 바이트코드 바로 옆 바이트 값인(0)을 읽어서 스택에 넣는다.

두 번쨰 INST_LITERAL을 실행한다.
이번에는 (10)을 읽어서 스택에 넣는다.

마지막으로는 INST_SET_HEALTH를 실행한다.
이 명령은 스택에서 10을 꺼내와 mount 변수에 10을 넣고 두 번째로 0을 스택에서 꺼내와 wizard 변수에 넣는 것이다.
이것으로 매개변수를 넣어서 setHealth 명령이 실행된다.
??? 오
매개변수를 넣을 수 있는 바이트코드가 스택으로 만들어졌다.
그렇다면 해당 인수만 바꿔서 해당 인수에 맞는 효과들을 넣어주면
우리는 마법을 자유자재로 바꿀 수 있게 되었다.
하지만 여전히 코드보다는 데이터로 보인다.
예를 들어서 체력을 주문력 스탯의 반만큼 회복하게 만든다.와 같은 식은 아직 불가능하다.
숫자로 된 하드 코딩보다는... 규칙으로 마법을 실행했으면 좋겠다는 것이다.
지금까지 만든 VM을 프로그래밍 언어로 본다면
아직 몇 가지 내장 함수와 상수 매개변수만 지원할 뿐이다.
바이트코드가 조금 더 행동을 표현할 수 있게 하려면 조합을 할 수 있어야 한다.
다시 말해서 정해진 값(하드코딩)이 아니라 ~~해서 이러한 값이 나왔고 해당 값을 이용하고 싶은 것이다.
앞서 말했듯이 마법사의 스탯에 의해 마법의 효과가 결정되게 하고 싶은 것이다.
스탯을 바꾸는 명령이 있으니 스탯을 얻어오는 명령을 추가해보자
case INST_GET_HEALTH:
{
int wizard = pop();
push(getHealth(wizard));
break;
}
case INST_GET_WISDOM:
case INST_GET_AGILITY:
// You get the idea...
이들 명령어는 스택에서 값을 뺐다가 넣었다 한다.
스택에서 매개변수를 꺼내어 어떤 마법사의 스탯을 보는 것이고
해당 스탯의 값을 읽어와서 다시 스택에 넣는 것이다.
이제 스탯을 복사하는 마법을 만들 수 있게 됐다.
하지만 아직 부족하다.
스탯을 복사해서 연산을 돌려 규칙을 만들고 싶다.
case INST_ADD:
{
int b = pop();
int a = pop();
push(a + b);
break;
}이 연산은 어떤가?
값 2개를 스택에서 빼와서 더한 결과를 다시 스택에 집어넣는 일이다.
이러한 연산과 스탯을 가져오는 것이 더해져서
0번 마법사의 체력을 Agt +Wis 의 절반만큼 더해주려고 한다.
코드로 생각하면 이렇게 될 것이다.
setHealth(0, getHealth(0) +
(getAgility(0) + getWisdom(0)) / 2);
이렇게 해서 숫자를 직접 지정하지도 않고 마법사의 스탯에 따른 규칙으로 숫자를 산출해냈다.
이 과정을 천천히 보자면
1. 마법사의 현재 체력을 가져와 저장
2. 마법사의 민첩을 가져와 저장
3. 마법사의 지력을 가져와 저장
4. 저장된 민첩과 지력을 가져와 더해서 저장
5. 해당 결과를 가져와 2로 나눈 뒤 저장
6. 마법사의 체력에 해당 결과를 더해서 저장
7. 해당 결과를 가져와 마법사의 체력으로 만듬.
가져와서 연산하고 저장한다.
이러한 단순한 과정만으로 위와 같이 마법을 만들었다.
바이트코드로 현재 체력 가져오기를 표현해보자.
LITERAL 0
GET_HEALTH0번 마법사의 체력을 가져오는 바이트코드가 되었다.
가져온 체력을 스택에 넣는 것이다.
이런 식으로 변환하게 되면 원했던 표현식을 담은 바이트코드도 얻을 수 있다.
위의 7번의 과정을 한 번 나누어서 스택과 같이 보자
마법사 스탯이 체력 45, 민첩 7, 지력 11이라고 해보자.
스택의 변화를 잘 생각해보자.
LITERAL 0 [0] # Wizard index
LITERAL 0 [0, 0] # Wizard index
GET_HEALTH [0, 45] # getHealth()
LITERAL 0 [0, 45, 0] # Wizard index
GET_AGILITY [0, 45, 7] # getAgility()
LITERAL 0 [0, 45, 7, 0] # Wizard index
GET_WISDOM [0, 45, 7, 11] # getWisdom()
ADD [0, 45, 18] # Add agility and wisdom
LITERAL 2 [0, 45, 18, 2] # Divisor
DIVIDE [0, 45, 9] # Average agility and wisdom
ADD [0, 54] # Add average to current health
SET_HEALTH [] # Set health to result
스택 변화를 단계별로 보고 있으면 데이터가 스택을 통해서 마법처럼 왔다 갔다 하는 걸 볼 수 있다.
0번 마법사를 저장하고 있는 0이 마지막에 사용된 것도 관찰이 가능하다.
이런 식으로 명령어를 추가할 수 있다.
VM만으로도 깔끔한 데이터 형태로 행동을 맘껏 정의가능하게 되었다.
"바이트코드", "VM" 과 같은 단어들이 익숙치 않지만
VM 구현 과정을 통해서 "행동"을 격리한다는 목표를 이루었다.
바이트코드에서는 정의해놓은 명령 몇 개를 통해서만 다른 코드에 접근할 수 있기 때문에
악의적인 코드를 실행하거나 잘못된 위치에 접근할 방법이 없다.
스택 크기를 통해 VM 메모리 사용량을 조절할 수도 있다.
실제로 바이트코드를 만드는 문제만 남았다.
지금까지는 사람 손으로 의사코드를 바이트코드로 컴파일 했다.
??
하지만.. 바이트코드를 직접 만든다는 것은.. 현실성이 없다.
앞서 말했듯이 바이트코드만으로 마법이 커스터마이징이 가능해졌다.
하지만 우리가 앞서 했던 방식은 저수준, low-level 방식이다.
그렇게 하면 유지 보수 변경이 겁나 어려워진다.
사용성을 높게 하지 않으면 그저.. 빛좋은 개살구다.
만든 사람밖에 못 만진다고 생각하면 쉽다.
아무튼 이러한 차이를 그복하기 위해서
툴이 필요하다.
툴을 이용해서 해당 마법에 대한 행동을 고수준으로 정의하고,
이를 저수준인 스택 머신 바이트코드로 변환할 수 있어야 한다.
우리가 기계어 대신 어셈블리어, 어셈블리어 대신 고수준 언어를 쓰는 것과 마찬가지다.
이런 툴을 만드는 것은 VM 만드는 것보다 어려워 보인다.
텍스트 기반 언어 컴파일은 이 책에서 다루기엔 너무 광범위해서 그렇지 아주 어렵지는 않다.
그리고 툴이 필요하다고 해서 꼭 텍스트 파일을 입력으로 받는 컴파일러여야 한다는 것은 아니다.
특히 툴 사용자가 프로그래밍에 익숙하지 않다면 더욱 GUI 를 이용해서 구현해야 편해진다.
문법 오류가 생기기 쉬운 텍스트 형식은.. 사용하기 어려울 것이다.

이와 같이 GUI로 구현하는 것이 좋다.
여기서는 오류가 생길 수 없다.
그냥 잘못된 길로 빠지면 창을 띄우거나 버튼을 비활성화하면 되니까.
아니 뭐 이것까지 해야해..?라는 질문에 대답을 하자면
바이트코드는 사용자가 편하게 사용하는 데에 있다.
우리가 아무리 저수준에서 구현을 잘해놨다고 해도
코드의 양이, 해야되는 작업의 양이 고수준의 10배라면 의미가 없다.
고수준으로 만들어서 효율을 높이는 것이 바이트코드 패턴의 목적 중 하나이다.
'Game Development, 게임개발 > 디자인패턴' 카테고리의 다른 글
| Object Pool, 오브젝트 풀, 객체 풀 [디자인패턴](최적화) (0) | 2021.10.17 |
|---|---|
| Subclass Sandbox, 하위 클래스 샌드박스 [디자인패턴](행동) (0) | 2021.10.17 |
| Update Method, 업데이트 메서드 ** [디자인패턴] (0) | 2021.10.09 |
| Game Loop Pattern, 게임 루프 패턴 ** [디자인패턴] (0) | 2021.10.07 |
| Double Buffer Pattern, 이중 버퍼 패턴 [디자인패턴] (0) | 2021.10.06 |