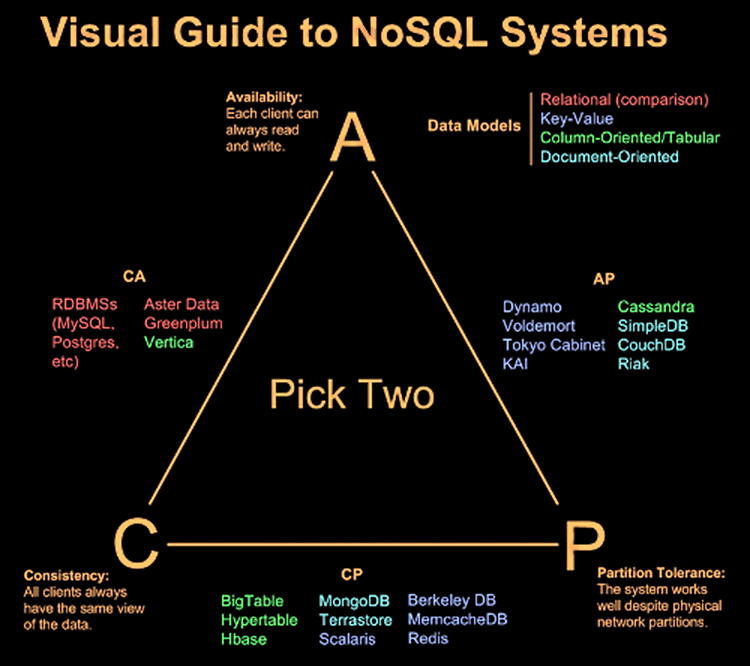
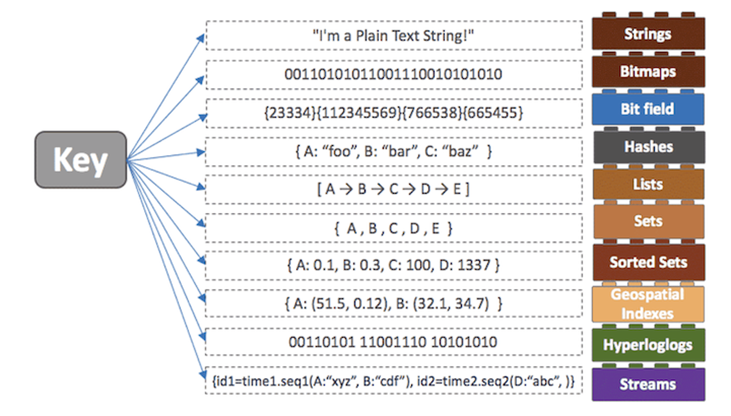
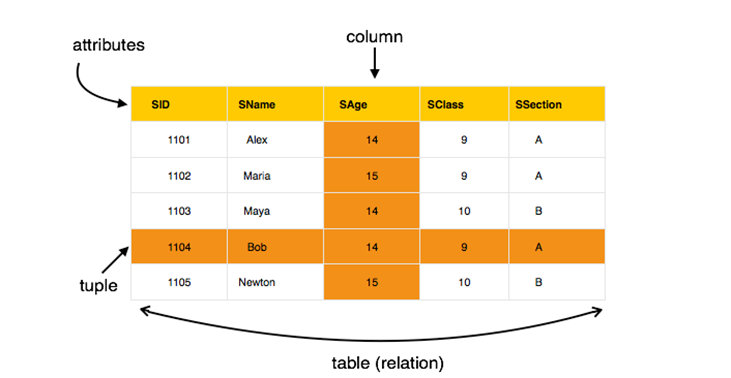
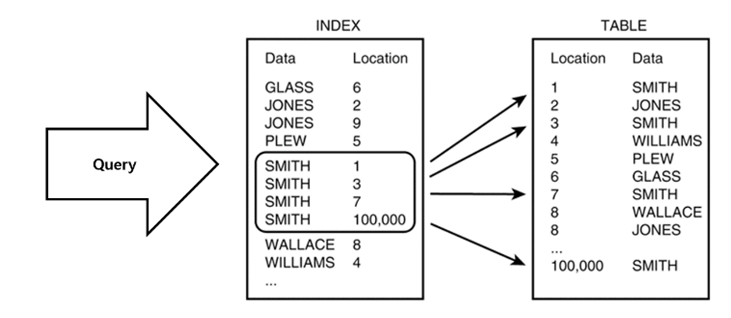
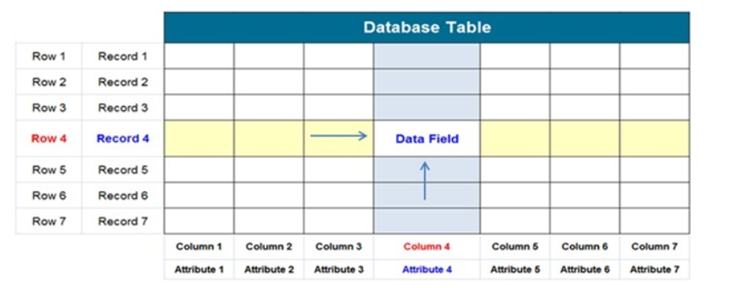
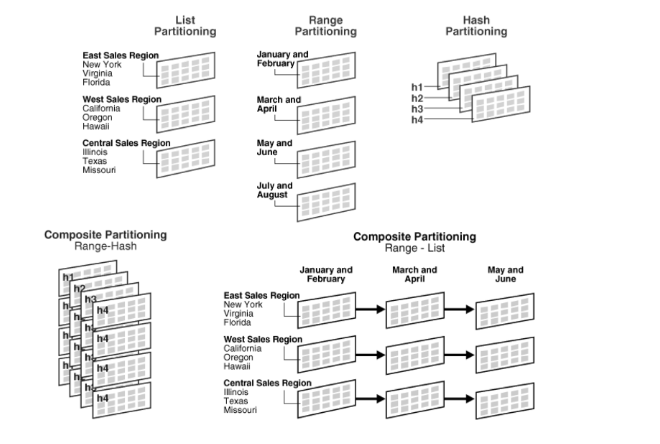
Not Only SQL 이란 뜻이다. 충분히 SQL도 복잡한데.. 왜 NoSQL이란게 나왔냐??라고 한다면 RDBMS처럼 요즘 많이 쓰는 관계형 DBMS의 한계를 극복하기 위해서 새롭게 수평적 확장을 할 수 있도록 만든 포맷이다. 알아보자 그렇다면 어떤 사람들이 NoSQL을 필요로할까???? 대표적으로 2가지라고 말할 수 있다. 데이터 규모의 확대되는 서비스 –저장할 데이터가 많아지면서 읽기/쓰기에 있어서 RDB가 제약 요소가 됨 –RDB의 수평적 확장성 한계로 새로운 해결책이 필요 웹 서비스처럼 구조가 변화무쌍한 서비스 –저장할 데이터의 형태가 계속 변화 –사용자의 데이터 요구가 일관적이지 않고 다양 NoSQL이 어떤 특징을 가지고 있는데??? 기본적으로 key & value 로 저장하지만 여러가가지로..