지역성이란 단어에서 알 수 있듯이
캐시와 관련되어 있다.
CPU 캐시를 최대한 활용할 수 있도록 데이터를 배치해 메모리 접근 속도를 높이기 위함이다.
우리는 무어의 법칙으로 CPU 성능이 18~24개월마다 반도체 성능이 거의 2배로 증가한다고 그랬지만..
이제 한계에 봉착했다.
즉, 우리는 있는 것을 더 잘 돌릴 수 있는 능력이 필요해졌다.
칩은 계속해서 연산 속도가 빨라지지만 데이터의 접근 속도는 그렇지 못했다.
즉, 캐시를 쓰는 것은 여전하다.

아무튼 각설하고 우리는 프로세서의 성능이 메모리의 성능보다 높아서 생기는 그 차이에 대한
비용을 어떻게 최소화할 것인가? 에 대해 생각해 봐야 한다.
우리가 회사 직원이라고 생각해보자
우리 업무는 숫자가 빽뺵이 쓰여있는 문서에 대해 작업한다.
이런 문서들은 해당 업무를 하는 직원들끼리만 아는 순서에 따라
특정한 이름표가 붙어 있는 상자를 찾아서 진행한다.
원래 성실하기 때문에 1분이면 서류 상자 하나를 끝낼 수 있다.
다만 진짜 문제는 여기에 있다.
모든 서류 상자는 다른 건물에 있는 창고에 보관되어 있다.
하지만 상자를 가져오려면 창고지기에게 부탁을 해야 한다.
창고지기는 지게차로 통로를 다니며 부탁받은 상자를 찾아다닌다.
이렇게 창고지기가 상자를 찾아서 가져오는 데에는 하루가 걸린다.
즉, 해당 상자를 처리하는데는 1시간만에 걸려도 해당 상자를 가져오는데 1일이 걸리니
뭐 1일동안 놀고 1시간 처리하고 무슨.. 상자 하나가 25시간이 걸린다.
그래서 우리는 생각했다.
1. 다음 작업에 필요한 서류 상자가 이전 서류 상자와 같은 선반 위에 있을 가능성이 높다
2. 지게차로 서류 상자 하나만 가져오는 것은 비효율적이다
3. 여기 사무실 구석에 작은 공간이 있다.
그래서 우리는 창고지기에게 상자를 요청할 때 해당 선반 전체를 통째로 요구하기로 했다.
그렇다면 우리는 1일에 가져오지만 선반 전체 중 20개의 상자가 우리가 작업할 것에 해당해서
20일에 끝낼 것을 20시간만에 끝낼 수 있게 되었다.
만약 주변 상자에 없다면 조금 귀찮은 일이었겠지만
해당되는 상자라면 우리 생산성이 정말 높아진 것을 알 수 있다.
이 이야기는
CPU 이야기다.
캐시 이야기고
RAM이야기다.
물론 SWAP 까지가서.. DISK까지 접근도 해당된다.
아래와 같이
어떠한 것을 요청했으면 그 주변을 다 가져온다.
이것을 캐싱이라고 하며 cache line을 가져온다고 한다.
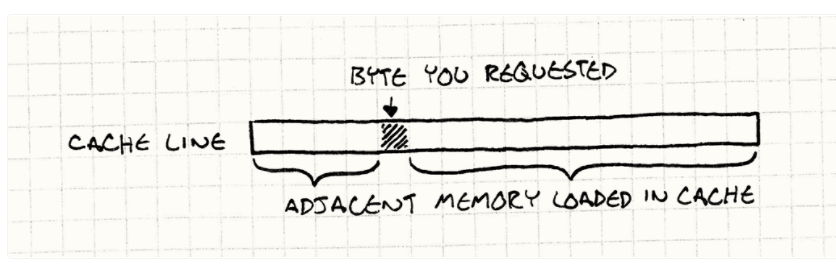
만약 가져온 캐시에 원하는 데이터가 있다면 바로 연산으로 넘어가면 된다.
만약 주 메모리에서 가져와야 하는 경우가 발생하면 그것이 바로 캐시 미스다.
캐시 미스가 발생하면 어쩔 수 없이 CPU는 멈춰야 한다.
다음 instruction을 진행할 수 없기 때문이다.
게임과 비슷한 프로그램을 캐시 라인을 최적으로 사용할 때와 최악으로 사용할 때로 나누어 만들어봤다.
캐시를 뒤엎는 코드를 벤치마킹해서 문제가 어느정도인지 확인해보자.
쉽게 말하면 성능이 얼마나 차이나는지 보자.
결과는.. 참혹했다.. 50배정도 차이가 났다. 하는 일이 같았음에도 성능은 50배가 차이났다.
같은 CPU임에도 성능이 50배가 차이났다.
즉, 우리가 CPU를 돌리는 데에 CPU가 대기하는 시간이 그만큼 많아지면 손해를 본다는 뜻이었다.
다시 말하면 CPU가 아무리 50배 좋은 것을 쓰더라도
기존 CPU의 캐싱을 잘만한다면 따라잡을 수 있다는 말이었다.
**물론 50배 좋은 CPU가 최악이어야 하겠지만 말이다.
즉, 우리는 가장 직접적으로 컴퓨터 성능에 대한 패턴을 적용한다고 봐도 무방하다.
코드 측면에서가 아닌 데이터를 어떻게 두느냐?의 측면이다.
어차피 캐싱의 모든 기법은 결론이 같다.
칩이 어떤 데이터를 읽을 때마다 캐시 라인을 같이 읽어 온다.
그리고 캐시 라인에 있는 값을 더 많이 사용할수록 더 빠르게 만들 수 있다.
즉, 자료구조를 잘 만들어서 처리하려는 값이 메모리 내에서 서로 가까이 붙어 있도록 하는 것이다.
다시 말해서 메모리는 수행하는 것들끼리 뭉쳐있어야 한다는 것이다.
아래 그림처럼
Thing, Another, Also 들이 뭉쳐있어야 Thing 실행되고 바로 Another 실행되고... 이렇게 되는 것이다.

이 패턴은 더욱 간단하다.
CPU의 캐시에 넣을 때 데이터 지역성을 높일 수 있도록 데이터를 처리하는 순서대로 연속된 메모리에 두자는 것이다.
**말은 간단한데.. 사실 어렵다.
그렇다면 이러한 패턴은 언제쓸까??
사실 모든 곳에 쓰는 것이 맞지만..
속된 말로 성능이 딸릴 때 쓴다.
성능이 충분하면 그다지 쓰지 않아도 좋다.
사실 최적화 기법은 성능이 문제가 있을 때 쓰는 것이 좋다.
왜냐하면 복잡하기 때문이다. 삶을 행복하게 살고 싶다면.. 충분한 장비를 갖추는 것과 비슷하다.
내가 발이 있는데 왜 자전거를 타야해???
물론 내가 달리기를 엄청 나게 연습해서 자전거보다 빨라질 수 있으나.. 굳이 해야하나..? 싶다.
이런 것도 안해?라고 해서 능력없는 개발자가 아니라.. 다른 것에 더 집중할 수 있다는 말이다.
아무튼 그렇다.
참고로 이 패턴은 성능의 문제가 캐시의 미스란 것을 밝히고 나서 시작하는 것이 좋다.
프로파일러로 한 번 돌려보면 각 나온다.
예제로 살짝 배워보자
데이터 지역성을 위한 최적화라는 힘든 길을 가기로 맘먹었다면
자료구조를 CPU가 처리하기 좋은 방법을 찾으면 된다.
연속 배열에 대해서 알아보자
class GameEntity
{
public:
GameEntity(AIComponent* ai,
PhysicsComponent* physics,
RenderComponent* render)
: ai_(ai), physics_(physics), render_(render)
{}
AIComponent* ai() { return ai_; }
PhysicsComponent* physics() { return physics_; }
RenderComponent* render() { return render_; }
private:
AIComponent* ai_;
PhysicsComponent* physics_;
RenderComponent* render_;
};
위 클래스에서 각 컴포넌트에는 벡터 몇 개 또는 행렬 한 개 같은 몇몇 상태와
이를 업데이트하기 위한 메서드가 들어있다.
class AIComponent
{
public:
void update() { /* Work with and modify state... */ }
private:
// Goals, mood, etc. ...
};
class PhysicsComponent
{
public:
void update() { /* Work with and modify state... */ }
private:
// Rigid body, velocity, mass, etc. ...
};
class RenderComponent
{
public:
void render() { /* Work with and modify state... */ }
private:
// Mesh, textures, shaders, etc. ...
};
월드에 있는 모든 개체는 거대한 포인터 배열 하나로 관리한다.
매번 게임 루프를 돌 때마다 3가지 작업정도를 한다.
1. 모든 개체의 AI 컴포넌트 업데이트
2. 모든 개체의 물리 컴포넌트 업데이트
3. 렌더링 컴포넌트를 통해서 모든 개체를 렌더링
많은 게임코드가 아래와 같이 구현한다.
순차적 수행이다.
while (!gameOver)
{
// Process AI.
for (int i = 0; i < numEntities; i++)
{
entities[i]->ai()->update();
}
// Update physics.
for (int i = 0; i < numEntities; i++)
{
entities[i]->physics()->update();
}
// Draw to screen.
for (int i = 0; i < numEntities; i++)
{
entities[i]->render()->render();
}
// Other game loop machinery for timing...
}
CPU 캐시에 대해서 생각하기 전에는 문제가 없어 보이지만
이것은 사실 모두를 두들겨 패는 것과 마찬가지다.
1. 게임 개체가 배열에 포인터로 저장되어 있어서, 배열 값에 접근할 때마다 포인터를 따라가면서 캐시미스가 발생한다.
2. 게임 개체는 컴포넌트를 포인터로 들고 있어서 다시 한 번 캐시 미스가 발생한다.
3. 컴포넌트를 업데이트한다.
4. 모든 개체의 모든 컴포넌트에 대해서 같은 작업을 반복한다.
???
이는.. 수많은 개체의 할당과 해제를 그냥 무지성으로 반복하는 것이다.

게임을 빠르고 쾌적하게 돌리고 싶다면 이렇게 하면 안된다.
조금 더 개선해보자.
포인터를 통해 게임 개체에 직접 접근하는 이유가
게임 개체에 있는 또 다른 포인터를 통해 컴포넌트를 접근하기 위한 것이다.
즉, GameEntity 자체에는 별 관심이 없다. 게임 루프에서는 그저 컴포넌트들만 있으면 되는 것이다.
음.. 그렇다면 우리는 각 역할의 컴포넌트들을 저장할만한 배열을 준비해보자.
아래와 같이 준비했다.
AIComponent* aiComponents =
new AIComponent[MAX_ENTITIES];
PhysicsComponent* physicsComponents =
new PhysicsComponent[MAX_ENTITIES];
RenderComponent* renderComponents =
new RenderComponent[MAX_ENTITIES];
배열에 컴포넌트 포인터가 아닌 컴포넌트 객체가 들어간다는 점이 중요하다.
모든 데이터가 배열 안에 나란히 들어 있기 때문에 게임 루프에서는 객체에 바로 접근할 수 있다.
while (!gameOver)
{
// Process AI.
for (int i = 0; i < numEntities; i++)
{
aiComponents[i].update();
}
// Update physics.
for (int i = 0; i < numEntities; i++)
{
physicsComponents[i].update();
}
// Draw to screen.
for (int i = 0; i < numEntities; i++)
{
renderComponents[i].render();
}
// Other game loop machinery for timing...
}
포인터 추적을 전부 제거했다.
메모리를 여기 저기 뒤지지 않고서도 연속된 배열 세 개를 쭉 따라가면 된다.

컴포넌트 배열이 위에 그림처럼 깔끔해졌다.
바뀐 코드는 쭉 이어져 있는 바이트 스트림을 CPU에 계속 넣어주고 성능을 개선시킨다.
캡슐화를 많이 깨먹지도 않았다.
물론 게임 루프에서 게임 개체를 통한 접근이 아니라 직접 컴포넌트들을 업데이트하기는 한다.
그렇지만 그 전에도 게임 루프는 컴포넌트들을 AI, 물리, 렌더링 순서대로 업데이트하기 위해서
entities[i] -> ai( ) -> update( ); 와 같은 식으로 컴포넌트에 접근하고 있었으니까
여전히 컴포넌트는 자기 데이터와 메서드가 있다는 점에서 캡슐화되어있다고 말할 수 있다.
그렇다고해서 GameEntity 자체를 없앨 필요는 없다.
GameEntity가 자기 컴포넌트에 대한 포인터를 가지도록 만들 수 있다.
이 때 포인터들을 이들 배열에 있는 객체를 가리킨다.
개념적인 "게임 개체"와 개체에 포함되어 있는 것 전부를
한 객체로 다른 코드에 전달할 수 있다는 점에서 "게임 개체"는 여전히 쓸모가 있다.
게임 루프가 성능에 민감하기 때문에 게임 개체를 우회해서
게임 개체 내부 데이터에 직접 접근했다는 점이 중요하다.
이번에는 파티클 시스템이다.
모든 파티클을 하나의 연속적인 배열에 두고 이를 간단한 관리 클래스로 래핑해보자.
class Particle
{
public:
void update() { /* Gravity, etc. ... */ }
// Position, velocity, etc. ...
};
class ParticleSystem
{
public:
ParticleSystem()
: numParticles_(0)
{}
void update();
private:
static const int MAX_PARTICLES = 100000;
int numParticles_;
Particle particles_[MAX_PARTICLES];
};
파티클 시스템의 업데이트 메서드는 아래와 같이 기본 기능만 한다.
void ParticleSystem::update()
{
for (int i = 0; i < numParticles_; i++)
{
particles_[i].update();
}
}
하지만 생각해보면 파티클 객체를 매번 전부 처리할 필요는 없다.
파티클 시스템에는 고정 크기 객체 풀이 있지만 풀에 들어있는
모든 파티클이 사용되는 것이 아닌 것처럼 쉽게 해결이 된다.
for (int i = 0; i < numParticles_; i++)
{
if (particles_[i].isActive())
{
particles_[i].update();
}
}
Particle 클래스에 플래그, flag 를 둬서 현재 사용 중인지를 알 수 있게 한다.
업데이트 루프에서는 모든 파티클에 대해서 이 값을 검사한다.
루프가 플래그 값을 캐시에 로딩하면서 나머지 파티클 데이터도 같이 캐시에 올린다.
파티클이 비활성화 상태라면 다음 파티클을 조사한다.
이때 같이 로딩했던 나머지 파티클 데이터는 무용지물이 된다.
활성 파티클이 적을수록, 메모리를 더 자주 건너뛰게 된다.
그럴수록 실제로 활성 파티클을 업데이트하기까지 더 많은 캐시 미스가 발생한다.
배열이 크고, 비활성 파티클이 많이 있다면 또 다시 캐시를 뒤엎어야 하기 때문이다.
아무리 객체를 연속적인 배열에 둔다고 해도
실제로 처리할 객체가 배열에 연속되어 있지 않다면 소용이 없다.
그렇다면 우리는 해당 배열을 정렬해야 한다.
활성 여부를 플래그로 검사하지 않고 활성 파티클만 맨 앞으로 모아두면 되겠다.
이미 앞에 모아놓은 파티클이 활성 상태라는 것을 안다면 따로 플래그를 검사하지 않아도 된다.
더해서 얼마나 많은 파티클이 활성 상태인지도 쉽게 알 수 있다.
업데이트 루프도 아래와 같이 바꾼다.
for (int i = 0; i < numActive_; i++)
{
particles[i].update();
}
더 이상 어떤 데이터도 건너뛰지 않아도 된다.
캐시에 올라오는 모든 바이트는 처리가 필요한 활성 파티클 데이터다.
**그렇다고 매 프레임마다 배열 전체를 퀵소트하라는 얘기는 아니다. 그랬다가는 득보다 실이 많아질 수 있다.
다만 활성 객체는 앞에 모아두자는 말이다.
이미 배열이 활성, 비활성 상태로 정리되어 있다고 해보자
당연히 처음에는 모든 파티클이 비활성 상태로 정리되어 있다.
다만 파티클이 활성화되면 이를 비활성 파티클 중 맨 앞에 있는 것과 바꿔서
활성 파티클 맨 뒤로 옮기게끔 한다.
void ParticleSystem::activateParticle(int index)
{
// Shouldn't already be active!
assert(index >= numActive_);
// Swap it with the first inactive particle
// right after the active ones.
Particle temp = particles_[numActive_];
particles_[numActive_] = particles_[index];
particles_[index] = temp;
// Now there's one more.
numActive_++;
}
파티클을 비활성할 때는 반대로만 해주면 된다.
void ParticleSystem::deactivateParticle(int index)
{
// Shouldn't already be inactive!
assert(index < numActive_);
// There's one fewer.
numActive_--;
// Swap it with the last active particle
// right before the inactive ones.
Particle temp = particles_[numActive_];
particles_[numActive_] = particles_[index];
particles_[index] = temp;
}
메모리에서 객체를 복사로 옮기기를 꺼리지만
포인터 할당보다는 장점이 있는데
바로 포인터 추적 비용까지 고려한다면 객체를 복사로 옮기는 것이 더 쌀 수 있다.
파티클을 활성 상태에 따라 정렬하면 파티클마다 활성 상태를 플래그에 저장하지 않아도 된다는 장점도 있다.
배열에서의 위치와 numActive_ 값으로 활성 여부를 유추할 수 있어 파티클 객체 크기를 좀 더 줄일 수 있고
이로 인해 캐시 라인에 객체를 더 많이 넣을 수 있어 속도를 늘릴 수 있다.
모든 것이 만족스럽지는 않다. API를 보면 알겠지만 객체지향성을 어느 정도 포기해야 한다.
Particle 클래스는 자신의 활성 상태를 스스로 제어할 수 없다.
자신의 인덱스를 모르기 때문에 activate( ) 같은 메서드를 스스로 호출할 수 없다.
파티클을 활성화하려면 꼭 ParticleSystem 클래스를 통해서 해야 한다.
마지막으로 사용 빈도 수에 따라 캐싱을 하는 기법을 설명해보겠다.
어떤 게임 개체에 AI 컴포넌트가 있다.
여기에는 현재 재생중인 애니메이션, 이동 중인 목표 지점, 에너지 값 등이 들어 있어서
프레임마다 이 값을 확인하고 변경해야 한다.
class AIComponent
{
public:
void update() { /* ... */ }
private:
Animation* animation_;
double energy_;
Vector goalPos_;
};
하지만 AI 컴포넌트에는 사용 빈도 수가 훨씬 적은 상태도 들어있다.
산탄총을 쏘는 적을 만나서 죽었을 때다.
죽었을 때 아이템을 떨어뜨리는데 그 데이터가 빈도수가 적다.
class AIComponent
{
public:
void update() { /* ... */ }
private:
// Previous fields...
LootType drop_;
int minDrops_;
int maxDrops_;
double chanceOfDrop_;
};
아까와 마찬가지로 AI 컴포넌트를 정렬된 연속 배열을 따라가면서 업데이트한다고 해보자.
??
데이터에 아이템 드랍 정보가 들어있다 보니 컴포넌트 크기가 커져서
캐시 라인에 들어갈 컴포넌트 개수가 줄었다.
읽어야 할 전체 데이터 크기가 크다 보니 캐시미스가 더 자주 발생한다.
드랍 아이템 정보는 업데이트에서 쓰지 않는데도 불구하고 매 프레임마다 캐시로 읽어온다.
해결책은 앞서 말했던 대로 사용하는 빈도에 따라 나누는 것이다.
update에 사용되어 매 프레임마다 필요한 빈번한, hot 데이터 상태,
그 반대로 자주 사용하지 않는 한산한, cold 데이터 상태로 나누어 모아놓는다.
빈번한 부분은 주요 AI 컴포넌트에 해당한다.
이들 값은 가장 자주 사용하기 때문에 포인터를 거치지 않고 바로 데이터를 얻는 것이 좋다.
한산한 부분은 옆으로 치워놓되 필요할 때를 위해 빈번한 부분에서 포인터로 가리키게 한다.
class AIComponent
{
public:
// Methods...
private:
Animation* animation_;
double energy_;
Vector goalPos_;
LootDrop* loot_;
};
class LootDrop
{
friend class AIComponent;
LootType drop_;
int minDrops_;
int maxDrops_;
double chanceOfDrop_;
};
이제 AI 컴포넌트를 매 프레임마다 순회할 때 실제로 사용할 데이터만 캐시에 올린다.
**한산한 데이터를 가리키는 포인터는 ..그래도 올라간다 ㅎ
하지만 데이터를 이렇게 나누기는 참 어렵다.
실제로 많이 쓰이는 데이터와 거의 쓰이지 않는 데이터를 분간하기도 어렵다.
즉, 이런 최적화 기법은 결국 많이 해봐야 아는 영역으로 우리는 천천히 느긋하게 배워보도록 하자.
'Game Development, 게임개발 > 디자인패턴' 카테고리의 다른 글
| Spatial Partition, 공간분할 [디자인패턴](최적화) (0) | 2021.10.27 |
|---|---|
| Event Queue, 이벤트 큐 [디자인패턴](디커플링) (0) | 2021.10.27 |
| Component, 컴포넌트 [디자인패턴](디커플링)** (0) | 2021.10.26 |
| Type Object, 타입 객체 [디자인패턴](행동) (0) | 2021.10.26 |
| Dirty Flag, 더티 플래그 [디자인패턴](최적화) (0) | 2021.10.21 |