비동기, Asynchronous 와 동기,Synchronous
블로킹,Blocking 과 논 블로킹 Non-Blocking
I/O 작업은 user space에서 직접 수행할 수 없기 때문에
user process가 kernel에 I/O 작업을 '요청'하고 '응답'을 받는 구조다.
응답을 어떤 순서로 받는지(synchronous/asynchronous),
어떤 타이밍에 받는지(blocking/non-blocking)에 따라 여러 모델로 분류되는 것이다.
일반적으로 4가지 개념에서 알아보자.
비동기 프로그래밍, 동기 프로그래밍이라는 말을 많이 듣는다.
우선
동기 작업이란 한 번에 하나씩 수행되는 것을 의미한다.
즉, 해당 작업이 끝나기 전까지는 현재 진행중인 작업 외의 다른 작업을 수행하지 못함을 의미한다.
**HTTP 요청은 요청을 하면 무조건 응답을 받는다. 이것이 동기적이라고 말할 수 있다.
다른 말로는

▶ 모든 I/O 요청-응답 작업이 일련의 순서를 따르는 것이다. 즉, 작업의 순서가 보장된다.
▶ 작업 완료를 user space에서 판단하고 다음 작업을 언제 요청할지 결정한다.
▶ 일련의 Pipeline을 준수하는 구조에서 효율적이다.
다시 말하면 현재 작업외의 다른 작업을 하지 못한다는 말은
작업의 순서를 보장한다는 것이고
작업의 순서를 보장한다는 말은 '현재 작업의 응답'을 받는 시점과 '다음 작업을 요청'하는 시점을 맞추는 일이다.
다음 작업이 있다는 것 자체가 순서가 있다는 것을 의미하며 결국 이전 작업이 완료되기 전까진 다음 작업이 수행되지 않는 것이다.
비동기 작업이란 한 번에 하나 이상이 수행될 수 있음을 의미한다.
즉, 현재 작업을 진행중이더라도 다른 작업을 수행할 수 있다.
또한 작업에 대한 결과를 바로 원하지 않는다.
**내가 이메일을 보내는 작업은 상대방이 바로 답장하기를 원해서 보내는 작업은 아니다.

▶ kernel에 I/O 작업을 요청해두고 다른 작업 처리가 가능하나, 작업의 순서는 보장되지 않는다.
▶ 작업 완료를 kernel space에서 통보해 준다.
▶ 각 작업들이 독립적이거나, 작업 별 지연이 큰 경우 효율적이다.
**만약 다중 요청에 대한 처리와 동시성 처리를 잘할 수 있다면 비동기 작업의 속도가 더 빠를 것이다.
보면 시간적으로 결과를 얻는 시간이 어디가 더 빠른 것인지 알 수 있다.

**여기서 Products와 Customers가 끝나고 Orders가 실행될 수 있는 이유는 무엇인지 생각해보자
저 3개를 한꺼번에 하는 것이 더 빠르지 않았을까?
동기적으로 처리해야하는 작업이 있고 비동기적 작업이 있는 것이다.
우리는 이미 동기성에 익숙해져 있지만 더 빠른 작업을 위해서는 비동기 환경을 잘 다룰 수 있어야 한다.
하지만 서로 의존성이 있는 곳에서 작업을 한다면
비동기는 오히려 오류를 불러올 가능성이 높다.
때문에 비동기 프로그래밍을 할 때는 서로 independent task에 대해서 수행하는 것이 좋다.
위의 그림 또한 각자 독립적인 작업을 수행하였기 때문에 비동기로 실행해서 좋은 결과를 얻은 것이다.
요약을 하자면
** 이것은 스레드에서 말하는 것이다.
동기는 내 작업을 끝낼 때까지 다른 작업을 수행하는 것을 막는다.
** 다른 Thread에서 다른 작업을 하면 될텐데...
-> 맞다. 다른 스레드에서 다른 작업을 하는 것은 괜찮다.
비동기는 내 작업을 끝내지 않더라도 다른 작업을 수행한다.
** 그래서 다른 Thread에서 한다. (대부분)
-> 비동기면 내 Thread에서도 Blocking TIme일 때 수행 가능하다.
I/O를 받아올 때 오버헤드가 큰 경우가 많은데
이런 경우를 동기로 처리한다면 I/O를 받아오기 전까지 해당 프로그램은 멈출 것이다.(Blocking)
즉, 그럴 때에는 비동기를 활용해서 프로그램이 돌아가도록 하는 것이 좋다.
-> 해당 Blocking 시간에 다른 작업을 한다는 뜻이다.
반대로 비동기 때문에 이전에 작업한 것들도 끝내지 않은 채
무지막지 하게 연산을 요구하는 작업을 한다거나 의존성이 있는 작업을 한다면
그것 또한 문제가 될 것이니 잘 알아서 하는 것이 좋겠다.
그림으로 더 알아보자
싱글 스레드에서 동기 작업 (싱글 스레드도 동기 가능)
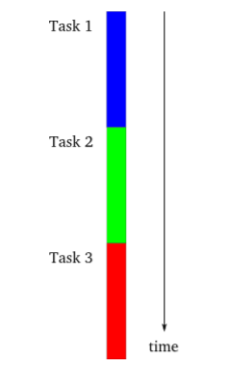
멀티 스레드 동기 작업 (멀티 스레드도 동기 작업 가능)
이건 멀티 프로세서 시스템의 OS가 각 스레드를 제어해서
동시에 task를 수행한다.
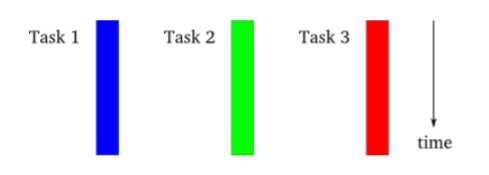
**하지만 특정 프로그램은 멀티 스레드가 아니라 멀티 프로세스를 사용해서 병렬수행하는 경우가 있다.
멀티프로세스도 위와 같은 형식으로 수행된다.
다음은 비동기적 수행이다.
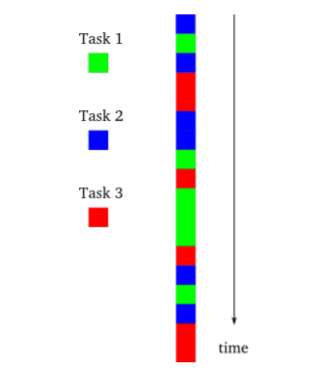
이건 싱글 스레드이지만 비동기적인 수행으로 진행될 경우다.
각 작업들이 interleaved 되어 있다.
어떻게 보면 이것이 더 복잡하다고 생각할 수 있지만
프로그래머 입장에선 이것이 더 간단하게 보이는데
그 이유는 해당 시간에 따라 어떤 작업이 진행되고 있는지 쉽게 알 수 있기 때문이다.
다시 말해서 위와 같은 비동기 모델에서는
현재하고 있는 작업을 다른 작업에 대한 제어 권한을 명시적으로 양도할 때까지 계속 수행한다.
즉, Blocking 시간에 수행할 작업을 명시적으로 정해주어야 한다는 말이다.
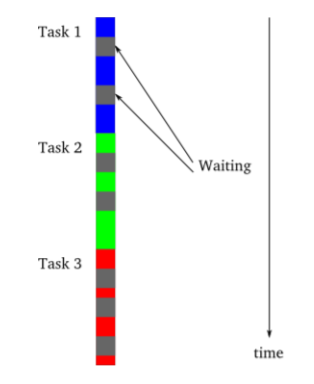
이것은 동기작업을 하는 것을 의미한다.
작업은 하되 blocking 영역도 그려놓았다.
** blocking 영역이란 해당 Thread가 사용되지 않고 있다고 생각해도 된다.
(CPU가 사용되지 않는 부분)
중간 회색 구역이 blocking(waiting)을 하는 것이 보인다.
이 Blocking은 해당 작업에 대한 대부분 I/O 또는 Memory R/W에 관한 것으로
CPU의 작업속도에 비해 많은 속도가 차이나서 생기는 구역이다.
다시 위의 두 그림을 보자
해당 회색 구역의 빈칸이 왼쪽과 관련이 있어보이는 것은
우연이 아니라 맞다.
즉, 비동기적 수행일 때는 Thread가 Blocking인 시간을 이용하여
해당 task 말고도 다른 작업을 할 수 있다는 말이다.
다시 요약하자면
비동기 작업의 목적은
동기적 작업에서 생기는 blocking(waiting) 영역도 효율적으로 사용하고자 하는 것이다.
유일하게 비동기 작업이 blocking 되는 경우는 더 이상 수행할 것이 없을 때이다.
동기와 비동기를 알아봤으니이번엔 (Non) Blocking에 대해서 알아보자.
주로 이러한 용어는 I/O의 읽기, 쓰기에 적용된다. (앞에서 언급했다.)
블로킹은 자신이 Waiting(Blocking)된 것을 의미한다.
Thread가 Blocking이 된다는 것은 CPU가 점유되어 실행되지 못함을 의미한다.
▶ 요청한 작업이 모두 완료될 때까지 기다렸다가 완료될 때 응답과 결과를 반환받는다. [대기 O]
▶ 요청한 작업 결과를 기다린다.(CPU를 점유한 채 ~> 점유한다고 사용한다는 것은 아니다)
논블로킹은 블로킹의 반대다. Wait하지 않고 그냥 수행된다.
자신이 호출되었을 때, 다시 말해서 System call을 받았을 때
제어권을 바로 자신을 호출한 쪽으로 넘기며
자신을 호출한 쪽에서 다른 작업을 할 수 있도록 하는 것을 의미한다.
자신은 그대로 작업을 이어 나간다.
Thread 가 Waiting 하지 않으므로 CPU 제어는 그대로다.
▶ 작업 요청 이후 결과는 나중에 필요할 때 전달받는다. [대기 X]
▶ 요청한 작업 결과를 기다리지 않는다. (CPU 점유 X)
▶ 중간중간 필요하면 상태 확인은 해볼 수 있다. (polling)
예를 들어서 Main Routine을 진행 중에
어떤 메서드를 만나면 SubRoutine으로 빠지게 된다.
해당 SubRoutine에 대한 작업을 끝내고 메인으로 다시 돌아와서 진행하면 Blocking
해당 SubRoutine에 대한 작업이 끝나든 말든 다시 메인을 이어서 진행하면 Non-Blocking
하지만 CPU는 한 번의 하나의 Instruction만 실행할 수 있다.
즉, SubRoutine의 작업도 진행되면서 내 작업도 진행한다..?
결국 Asynchronous 와 Non-Blocking은 붙어서 사용되는 경우가 다수다.
우선 의미는 이해하겠는데
왜를 알아보자.
왜 블로킹을 하고 안하고 정해야할까?
블로킹을 하는 이유는 해당 작업이 끝나지 않은 채로 다른 작업을 진행한다고 하자.
뒤따라온 작업이 앞선 작업의 결과에 의존적인 작업이라면 예상치 못한 결과가 나올 수 있어서 그렇다.
논블로킹은 당연히 서로의 작업이 의존적이지 않아서 하는 것이라고도 할 수 있다.
** 내가 공부하고 있는데.. 펜을 강제로 뺏어서 펜돌리기에 쓰려는 것이다.
펜돌리기에 쓴다면 내가 공부한 것과 상관없기에 뺏겨도 된다만
그 펜을 내가 공부한 것을 베끼기 위해 쓴다고 하면내가 펜을 뺏겼는데
어떻게 공부한 것을 작성할 수 있겠는가? 라고 생각해보자
참고로 그림 하나 보자.
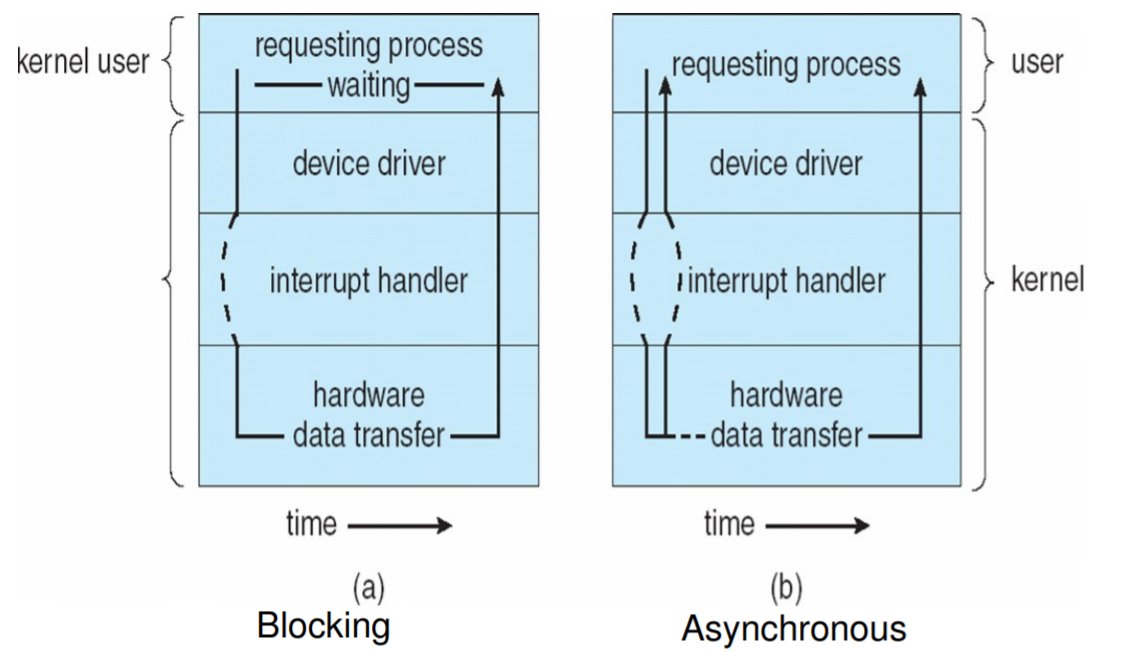
정확하게 구분을 한다기보다
그냥 의미를 받아들이자.
동기와 비동기는 구분이 확실하고
블로킹과 논블로킹도 구분이 확실하지만
잠깐 이 글도 살짝만 보자
하지만 blocking과 synchronous는 독립적인 개념이다.
예를 들어 block된 동안 다른 작업이 끼어들 수 있냐 없냐는 순서의 문제이므로 synchronous/asynchronous와 관련있다.
더해서 여러 작업을 처리하는 상황에서도 한 작업을 시작해두고
또 다른 것도 처리(non-blocking) 해야 효율적이기 때문에 각 작업이 독립적인 경우가 많았고
그리고 종료 시점이 달라도(asynchronous) 상관없는 게 대부분이었을 뿐이다.
non-blocking은 asynchronous과 비교되는 개념이 아니다.
그래서 쓰레드로 예시를 들 수 있다.
동기, Sync - Thread는 작업을 끝내야 다른 작업을 진행할 수 있다.
(블로킹과 비슷하지만 Waiting Queue에 들어가지 않아도 된다)
블로킹, Blocking - Thread는 Waiting Queue에 들어가게 된다.
논블로킹, Non-Blocking Thread는 작업이 끝나든 말든 다른 작업을 이어서 한다.
(당연히 Thread는 Waiting Queue에 들어가지 않는다)
비동기, Async - Thread가 작업 중이면 Another Thread에서 다른 작업을 하는 것이다.
다시 말해서
Thread가 Blocking으로 작업을 수행한다면 해당 Thread는 Waiting Queue로 들어가고
Waiting Time 동안 해당 Thread를 비동기적으로 수행시킬 수 있다.
Thread가 Non-Blocking으로 작업을 수행한다면
Thread가 CPU를 계속 점유한 채로 수행된다.
여기서 동기 비동기 개념만 추가하면 되겠다.
해당 Thread가 하는 일에 대해서 Sequential하게 수행할 것인가 아니면 Simultaneous 하게 할 것인가.
참고
그렇다면 위의 작업이 아닌 Transmission, 전송에선 어떨까?
동기식 전송과 비동기식 전송에 대해 살짝 알아보자
동기식 전송이란 Timing Signal에 맞추어서 데이터 스트림을 전송하는 방식을 말한다.
(클럭을 말한다 -> 클럭에 따라 데이터를 전송하고 수신함)
이런 방식은 방대한 크기의 데이터를 전송할 때 많이 쓰인다.
비동기식 전송이란 송신자는 데이터를 보내고 수신자는 Flow Control, 흐름 제어를 사용해서 받는다.
송신자 측과 수신자 측의 데이터를 동기화하기 위해 클럭같은 것은 쓰지 않는다.
비동기식 전송에서는 1 Character나 8-bit로 보통 보내는데
전송을 시작한다는 start bit('0')를 보내면서 전송을 시작하며
전송 한 번이 끝나면 stop bit('1')를 보낸다.
즉, start bit (1) + 데이터(8) stop bit(1)로 총 10 bit를 보낸다.
바로 비교를 하자면
동기식 전송에서는 사용자는 서버로부터 응답을 받기 전에 전송이 완료될 때까지 기다려야 한다.
-> 즉, 전송이 완료되고 나서야 서버로 부터 응답을 받을 수 있는 것이다.
다시 말하면 응답을 받는 것 까지가 동기식 전송의 끝이다.
비동기식 전송에서는 전송이 완료되지 않아도 서버에게 응답을 받을 수 있다.
-> 동기식에서는 전송이 끝나야 응답을 받을 수 있는 것과 다르다.
응답을 받지 않아도 전송이 가능하다.
또한 동기식 전송에서는 전송 단위가 프레임이나 블럭이지만
비동기식 전송에서는 앞서 말했듯이 8-bit 이다.
앞서 빠른 수행 때문에 비동기식 작업을 했다면
여기서는 동기식 전송이 빠르고 비동기식 전송이 느리다.
다만 동기식 전송은 비용이 크고 비동기식 전송은 비용이 작다.
https://www.guru99.com/difference-between-synchronous-and-asynchronous-transmission.html
https://cs.brown.edu/courses/cs168/f12/handouts/async.pdf
https://m.blog.naver.com/n_cloudplatform/222189669084
'CS Interview' 카테고리의 다른 글
| 운영체제 - CS 면접 총정리 (0) | 2021.11.22 |
|---|---|
| 교착상태, Deadlock (0) | 2021.11.01 |
| Paging, 페이징이란?(+단편화) (0) | 2021.10.10 |
| 삽입 정렬, Insertion Sorting 에 대하여 (0) | 2021.09.15 |
| CPU Bound와 I/O Bound의 차이 (0) | 2021.09.09 |