쿠버네티스 공식홈페이지가 있지만.. 그것보다 쉬운 설명이 있다고 믿고.. 내가 더 쉽게 쓸 수 있다고 믿는다.
이를 읽음으로써 더 이해가 잘 간다면 피드백 부탁한다.
원하는 용어는 Ctrl + F 로 잘 찾기를 바란다.
쿠버네티스 오브젝트(Kubernetes Object)란 무엇일까??
- 쿠버네티스 시스템 안에서 영속성(persistence)를 가지는 오브젝트이다.
- 클러스터의 상태를 나타내는 주체이다.
영속성...? 계속 끝까지 남아있는다는 말인가???
그럼 왜 그 오브젝트가 남아있어야 하는데??
오브젝트는 쿠버네티스를 운영하는데 많은 정보들을 제공해준다.
- 어떤 컨테이너화 된 어플리케이션이 어느 노드에서 동작 중인지
- 해당 어플리케이션이 이용할 수 있는 리소스는 뭔지
- 어플리케이션이 어떻게 재구동, 업그레이드 되어야 하는지에 대한 정책
더 있지만 대표적으로 위 3가지다.
그러한 오브젝트는 어떻게 생성하는데???
- apiVersion(쿠버네티스 API)
- kind(오브젝트 종류)
- metadata(오브젝트 구분 가능 데이터)
- spec(의도하는 상태)
Probe란 무엇일까??
가장 대표적인 역할로는
주기적으로 체크한 후, 문제가 있는 컨테이너를 자동으로 재시작하거나 또는 문제가 있는 컨테이너를 서비스에서 제외시키는 역할
이러한 작동은 어떻게 진행되느냐??
여기서 추가적으로 Handler에 대해서 더 자세히 말하자면


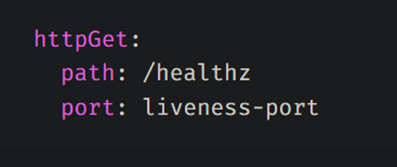
kubelet은 실행 중인 컨테이너에 대해 3가지 프로브를 지정할 수 있는 것이다.
- 1. Liveness(컨테이너가 살아있는지 아닌지)
- 애플리케이션의 상태를 체크해서 서버가 제대로 응답하는지 혹은 컨테이너가 제대로 동작중인지를 검사한다. Pod은 정상적인 Running 상태이지만, 애플리케이션에 문제가 생겨서 접속이 안되는 경우를 감지한다. (메모리 오버플로우 등) 문제를 감지하면 Pod을 죽이고 재실행하여 애플리케이션의 문제를 해결한다. (Restart Count 증가)
- 2. Readiness(컨테이너가 서비스가 가능한 상태인지 아닌지)
- 컨테이너가 요청을 처리할 준비가 되었는지 확인하는 probe이다. Pod이 새로 배포되고 Running 상태여도 처음에 로딩하는 시간이 있기 때문에 이 시간 동안은 애플리케이션에 접속하려고 하면 오류가 발생한다. Readiness probe는 어플리케이션이 구동되기 전까지 서비스와 연결되지 않게 해준다. (Readiness Probe가 실패할 때 엔드포인트 컨트롤러가 파드에 연관된 모든 서비스들의 엔드포인트에서 파드의 IP주소를 제거한다. ) Liveness Probe와 비교했을 때 어떤 차이가 있냐면, Liveness Probe는 probe 핸들러 조건 아래 fail이 나면 pod을 재실행 시키지만 Readiness Probe는 pod을 서비스로부터 제외시킨다. (Restart Count 증가 x)
- 3. Startup
- 컨테이너 내의 애플리케이션이 시작되었는지를 나타낸다. startup probe가 주어진 경우, 성공할 때 까지 다른 나머지 prob는 활성화 되지 않는다. 만약 startup probe가 실패하면, kubelet이 컨테이너를 죽이고, 컨테이너는 재시작 정책에 따라 처리된다.
좀 더 자세히 알아보자면
Probe를 사용하는 곳은 참 많다.
단적으로 HPA에 이용하는데 Scale Out, Scale In에서 트래픽이 유실될 때가 있을텐데.. 다 이런 작업 안해줘서 그렇다.
역시 Probe를 해놓는 것이 안전하다.

Scale Out 과정일 때는 파드가 점점 증가한다.
Deployment로 파드와 ReplicaSet을 관리하고
Service와 Ingress를 사용하여 애플리케이션을 외부로 노출한다.
때로는 파드의 컨테이너가 어플리케이션이 준비가 되지 않았음에도 status가 Running으로 표시되어 파드도 Running이 되었고 트래픽이 유실될 수 있음.
=> 모든 컨테이너의 준비가 끝나고 트래픽이 유입되어야함
Container probes를 설정하자 그래야... 트래픽이 유실되지 않는다..?
이거 은근히 실패요인 중 하나다..?
설정 몇개 예시로 볼까?
.spec.lifecycle에 써놓는 것으로 기억한다.


그럼 Scale In일 때는 어떻게 해???
파드의 종료를 요청했을 때 Pod는 Terminating이 되어 컨테이너에 정의된 container lifecycle hooks의 preStop이 실행되어 동시에 Service와 Ingress에서는 파드를 제거해서 추가 트래픽 유입이 없다.
preStop이 정의되지 않았거나 실행이 끝났다면 컨테이너 이미지에 정의된 STOPSIGNAL, SIGTERM 신호를 컨테이너의 기본 프로세스에 전송하여 안전하게 종료되도록 요청 후 파드가 삭제된다.
이러한 과정에서 파드와 컨테이너가 terminationGracePeriodSeconds 로 정의된 시간 또는 기본 값인 30초가 지난 후에도 동작하고 있다면 SIGKILL 시그널을 컨테이너의 모든 프로세스에 전송하고 파드를 강제 종료한다.
kubectl이 관리하는 컨테이너는 container lifecycle hooks의 postStart와 preStop을 통해 컨테이너 라이프사이클의 특정 지점에서 실행할 이벤트를 트리거할 수 있으며, 그 중 preStop은 컨테이너가 Terminated 상태에 들어가기 전에 실행된다.
preStop이 끝난 컨테이너는 이미지에 정의된 STOPSIGNAL 또는 SIGTERM 신호를 전송받고 프로세스가 안전하게 종료되어 파드가 종료되므로 Service와 Ingress에서 파드가 제거되어 트래픽이 차단된 후 파드의 종료가 시작되도록 하면 된다.
충분히 안전한 파드 종료를 위해서 terminationGracePeriodSeconds와 .lifecyccle.preStop을 추가하자.

Probe가 쓰는 경우가 실무에 진짜 많냐고..??
겁나 많다.
없으면 에러는 얘 때문일 수 있다.
WAS를 이용하는 경우 그냥.. 준비도 안되어있는데 트래픽 들어가면 오류뜬다.

특히 Readiness가 많이 쓰는데.. 조금 더 자세히 살펴보자.
Readiness Parameter
- -initialDelaySeconds
- -periodSeconds
- -timeoutSeconds
- -successThreshold
probe를 ‘실패’로 인식하기 위한 연속 failure 횟수 (default : 3 times)
★★★특히
Readiness Probe 자체는 해당 Task를 컨테이너가 수행할 수 있는지 확인하기 위해서 쓴다.
다시 말해서 Probe response가 제대로 오지 않거나 지연되서 오는 경우, 서비스를 할 수 없다고 판단하게 된다.
결국 Probe status 가 failure가 된다면 Kubernetes는 해당 파드의 엔드포인트를 서비스에서 제거해서 이용할 수 없게 할 것이다.
대표적으로 2가지 에러를 일으키는 요인이 있다.
쿠버네티스에서의 리소스란?
- 쿠버네티스에서는 컨테이너 단위로 리소스 제한 설정이 가능
- 각 서비스에 맞는 리소스를 제한하는 것이 효율적
- 기본적으로는 CPU, 메모리를 제한할 수 있지만 Device Plugin 사용 시 다른 리소스에 대해서도 제한 설정 가능
- CPU, Memory
- CPU는 millicores 단위로 지정한다.
- 1 vCPU = 1000m
- 메모리는 우리에게 익숙하진 않은 i를 쓴다.
- 1G = 1000M, 1Gi = 1024Mi
- 리소스 제한은 YAML 파일의 컨테이너 정의 부분에 포함된다.

- 리소스
- Request: 사용하는 리소스의 최솟값을 지정
- Limits: 사용할 리소스의 최댓값 지정
- Request와 달리 노드에 Limits로 지정한 리소스가 남아있지 않아도 스케줄링됨
- 일반적으로 Request의 리소스가 Limits 보다 리소스가 많다. => Request랑 Limit이 같은 경우 의미없음
- 참고
- kubectl get nodes -o yaml 로 확인할 수 있는 것은 노드의 총 리소스 양 (capacity)과 할당 가능한 리소스 양 (allocatable) 뿐이므로, 현재 리소스 사용량을 확인할 때는 kubectl describe node를 사용해야 한다.
- Requests만 설정한 경우 Limits는 자동으로 설정되지 않고, 호스트 측의 부하가 최대로 상승할 때 까지 리소스를 계속 소비하려고 한다. 그 때문에 이런 파드가 많이 기동하는 노드에서 리소스 뺏기가 발생하고, 메모리의 경우 OOM(Out Of Memory)으로 인해 프로세스 정지로 이어지게 된다.
- 반대로, Limits만 설정한 경우에는 Limits와 같은 값이 Requests에 설정되게 되어있다. 오버커밋되는 경우 Limits뿐만 아니라 명시적으로 Requests도 설정하도록 하자.
그렇다면 만약에..리소스 제한을 뛰어넘는 작업이 있다면?

Pod CPU 요청(Request)을 낮게 유지하면 Pod가 예약되기 쉽다.
CPU 요청(Request)보다 큰 CPU 제한(Limit) 을 사용하면 다음 두 가지를 수행할 수 있다.
- Pod는 사용 가능한 CPU 리소스를 사용하는 활동 버스트를 가질 수 있음
- 버스트 동안 Pod가 사용할 수 있는 CPU 리소스의 양은 적절한 양으로 제한
-Memory Utilization(메모리 사용률)
실제 메모리 사용량을 모니터링 하면서 충분한 메모리를 할당해주어야 한다.
그렇지 않으면 OOM에러가 뜨며 파드가 제거된다.
그렇다고 반대로 메모리를 너무 크게 할당한다면 다른 파드 스케줄링에 노드가 할당되지 못하는 결과로 이어질 수 있다.
노드 자체에서 사용 가능한 메모리가 부족하면 kubelet이 리소스를 회수하는데 kubelet이 파드를 제거할 수 있다.
컨트롤 플레인에서 리소스가 충분한 다른 노드에서 제거된 파드를 다시 스케줄링하려고 한다.
파드의 메모리 사용량이 정의된 요청을 크게 초과하는 경우는 kubelet이 해당 파드의 제거 우선 순위를 지정할 수 있으므로 요청과 실제 사용량을 비교하여 제거에 취약한 파드를 찾을 수도 있다.
습관적으로 요청을 초과하게 되면 파드가 적절하게 구성되지 않았음을 나타내는 것이다.
파드의 요청기반으로 스케줄링을 하기 때문에 스파이크 상황이나 메모리 증가에 대한 가용 리소스가 충분히 없는 노드에 파드가 스케줄링될 수 있다. 이는 파드가 언제든지 제거될 수 있는 노드에 스케줄링됨을 말한다.
-파드의 Memory Limit 과 파드의 Memory Utilization
Limit은 컨테이너에 할당될 최대 메모리 양을 나타낸다.
기본 제한 값이 없는 경우는 노드의 사용 가능한 메모리 전체를 사용할 수 있다.
다시 말해서 노드에서 실행되는 모든 파드에 대한 limit의 합계가 해당 노드의 할당 가능한 총 메모리보다 클 수 있다.
그래서 노드의 kubelet은 할당을 할 때 최소한 request를 만족한다면 리소스 할당을 최대로 줄인다.
=> 최소한의 리소스만큼만 할당한다.
메모리를 압축할 수 없는 리소스이기 때문에 지정된 제한과 관련된 파드의 실제 메모리 사용량을 추적하는 것이 정말 중요하다. 다시 말해서 파드가 정의된 limit 보다 많은 메모리를 사용하는 경우 파드는 제거된다.
파드의 메모리 사용량을 구성된 제한과 비교하면 OOM이 종료될 위험이 있는지 여부와 해당 limit이 타당한지 여부를 알려준다.
파드의 제한이 표준 메모리 사용량에 너무 근접하면 예기치 못한 스파이크로 종료될 위험이 있다.
그렇다고 해서 너무 메모리 할당을 많이 해버리는 것도 스케줄링에 악영향을 준다.
-Memory Request 와 Allocatable Memory
할당 가능한 메모리는 파드에 사용할 수 있는 노드의 메모리 양을 말한다.
=> 파드가 가지고 있는 Limit과는 다르다.
메모리 용량은 정적 값으로 처음에 결정되지만 각 노드의 할당 가능한 메모리와 비교하여 각 노드의 파드 메모리 요청 합계를 알고 있어야 한다. 다시 말하자면 노드에 할당된 모든 파드의 메모리 요구 사항을 충족하기에 충분한 용량을 가지고 있는지를 파악해야 컨트롤 플레인이 새 파드를 스케줄링을 할 수 있는지 여부를 알 수 있다.
스케줄링은 여러 기준을 사용해서 파드를 배치하기 때문에 특히 메모리 요청 리소스를 비교하면 클러스터에서 원하는 수의 파드를 시작하고 실행할 때 발생하는 문제를 해결할 수 있다.
클러스터의 현재 파드 수가 원하는 파드 수보다 적은 경우는 노드에 새로운 파드를 호스팅할 리소스 용량이 없기 때문인데 간단하게 해결하려면 클러스터에 더 많은 노드를 프로비저닝 하면 된다.
-Disk Utilization
메모리와 마찬가지로 압축할 수 없는 리소스로, kubelet이 볼륨에서 디스크 공간 부족을 감지하면 파드를 스케줄링할 때 문제가 생긴다. 노드의 남은 디스크 용량이 특정 리소스의 임계값을 초과하면 디스크 압력이 있다고 감지된다.
이렇게 임계값을 넘어가면 kubelet이 GC를 하고 GC 이후에도 리소스가 확보되지 않으면 파드를 제거한다. 노드 수준에서 디스크 사용률도 고려하고 파드 수준에서도 고려해야 한다. 이를 통해 어플리케이션 또는 서비스 수준에서의 문제를 방지할 수 있다.
-Node CPU Request 와 Node Allocatable CPU
메모리와 마찬가지로 Allocatable CPU는 파드 스케줄링에 쓰이는 노드의 CPU 리소스를 반영하고
CPU Request는 노드가 파드에 할당하려고 시도하는 최소 CPU 리소스이다.
다시 말해서 노드는 CPU를 최소 해당 파드의 Request CPU 만큼 제공하려고 한다.
노드당 전체 CPU Request를 알아내고 실제 노드가 Allocatable CPU 의 리소스의 차이를 비교해서 클러스터가 얼마나 파드를 만들 수 있는지 알 수 있다.
-파드의 CPU Request 와 파드의 CPU Utilization
실제 사용중인 CPU 양과 비교하여 노드가 파드에 할당할 최대 CPU 양을 추적할 수 있다.
메모리와 다르게 CPU는 압축 가능한 리소스다.
즉, CPU Limit을 초과하는 경우가 있는데 노드가 실제로 해당 파드에 사용 가능한 CPU 양을 조절할 뿐이지 파드를 제거하지는 않는다.
=> 메모리는 부족하면 다른 파드를 제거하게 된다.
다시 말해서 파드가 종료되지 않더라도 실제 이 수치를 모니터링하는 것은 스케줄링이나 실제로 의도한 리소스를 사용하는지 중요한 수치가 된다.
-CPU Utilization
파드가 사용하는 CPU 의 양과 노드 수준의 CPU 사용률을 추적하면 클러스터 성능에 대한 Insight를 얻을 수 있다.
파드가 CPU Limit을 초과하는 것과 마찬가지로 노드 수준에서 사용 가능한 CPU가 부족하면 노드가 각 파드에 할당된 CPU 양을 조절할 수 있다.
다시 말해서 CPU request, limit와 비교하면서 실제 사용률을 측정하면 실제로 2가지 항목이 제대로 실행되고 있는지 확인할 수 있고 예상보다 지속적으로 limit을 초과한다면 식별하여 해결해야 하는 파드로 문제 인식할 수 있다.
-HPA
500 * 0.1 = 50 이므로 50m 만 쓰여도 pod 가 확장되기 시작한다.
'클라우드 > Docker & K8s' 카테고리의 다른 글
| Docker_Window (0) | 2023.01.21 |
|---|---|
| 구글 스터디잼 (0) | 2022.10.21 |
| 쿠버네티스 - Probe (1) | 2022.07.30 |
| 쿠버네티스 - 디플로이먼트 yaml 파일 예시, Kubernetes - Deployment.yaml sample (0) | 2022.07.30 |
| 쿠버네티스 기본 개념 (3) | 2022.07.09 |