그냥 참고하고
알아보자

메모리는 주소로 관리했지만
파일은 이름으로 정보를 저장하는 방식이라고 볼 수 있다.
또한 OS에서 다양한 장치들을 file이라고 부르기도 함.
리눅스를 배우면 알 듯이
파일로 할 수 있는 연산은 create, delete, read, write, open, close 등이 있다.
meta data는 어떤 것이 만들어질 때 관련 정보들이 자동으로 생성되어 같이 저장되는 것을 의미하는데
파일을 생성할 때에도 마찬가지다.
**open은 file의 meta data를 메모리에 올려놓는 것을 의미한다.
그래서 결국 File System이란
OS에서 파일을 관리하는 부분, 관리하는 방법, 파일에 대한 모든 것이다.

Directory라는 말 많이 들어봤을 것이다.
경로라는 말로 해석되는데
Directory 또한 파일로 메타 데이터를 내용으로 하는 특별한 파일이다.
관련 연산은 위에 나와있다.
Partition이라는 것도 나오는데 운영체제가 보는 것은 논리적인 디스크이다.
** 우리가 하드디스크드라이브가 한 개임에도 C,D드라이브를 만들 수 있는 것과 같은 원리다.
위에서 Open 연산에 대해 meta data 관련해서 설명을 했는데
Open을 알아보자
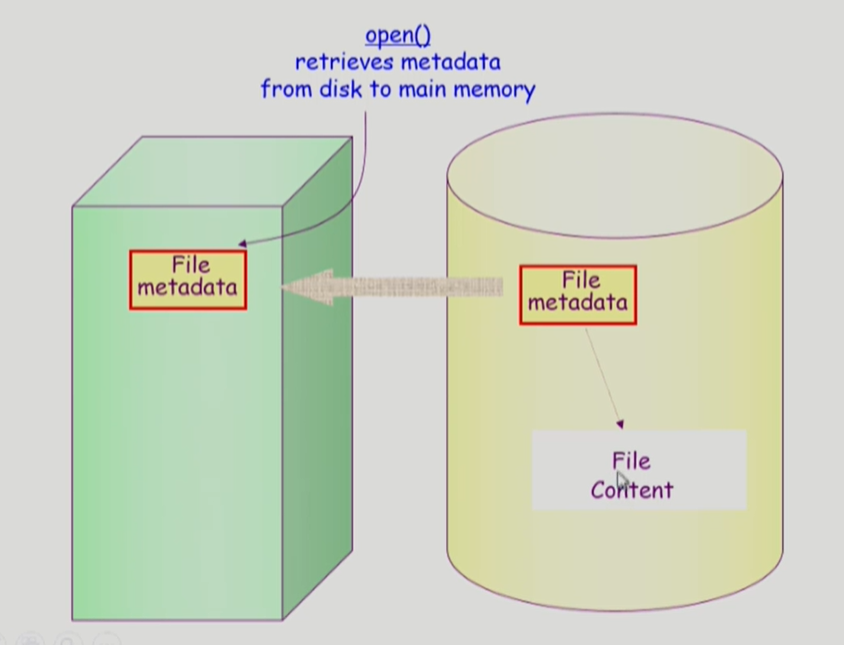
파일을 open하게 되면
해당 파일의 meta data가 메모리에 올라오게 된다.
아래의 예시와 그림을 통해 알아보자
/a/b/c를 찾는 작업이다.

아래 그림은 root 부터 c까지 가는 과정을 보여주는 그림이다.




** fd 는 file directory이다.
b의 metadata를 얽고 사용자에게 바로 전달하는 것이 아니라, 운영체제가 읽고 저장한 것을 준다.
다른 프로그램이 동일한 접근을 하면 바로 줄 수 있기 때문이다.
해당 장치 역시 버퍼, 캐시 같은 역할인데
이 또한 교체 시 LRU 알고리즘을 쓰는 것이 일반적이다.
또한 데이터 간에는 서로 Protection이 필요한 것처럼
파일에도 Protection이 필요하다.

파일은 여러 프로세스가 접근이 가능하다.
그래서 접근 권한과 어떠한 연산이 가능한 지에 대해 같이 가지고 있어야 한다.
3가지 방법으로 구현이 된다.
**행렬로 만들면 희소 행렬이 되기 때문에 (거의 1이 없고 0만 있는)
sparse matrix, 는 비효율적이기 때문에 별로 쓰지 않는다.
일반적으로
Grouping 방법이 쓰인다.
총 9개의 비트로 표현이 가능하기 때문에 효율적이라고 볼 수 있다.
**인스타나 페이스북의 나만보기, 친구 공개, 전체 공개 3가지로 분류되는 것처럼
Grouping도 그런 원리라고 보면 된다.
Password는 모든 파일에 대해, 권한에 대해 설정하는 것을 의미한다.
아까 Disk를 Partition으로 나누어 관리한다고 했는데
만약 다른 Partition에 있는 File System에 접근하려고하면 어떻게 해야할까?
Mounting이라는 연산이 있다.


다른 File system의 Root directory를 추가시킴으로써 다른 파티션에 접근할 수 있다고 보면 된다.
파일은 그렇다면 어떤 방식으로 접근하게 될까?
일반적으로 2가지 접근이 있다.
순차 접근, 직접 접근이다.
자료구조를 배웠다면 여기서도 비슷하게 적용되겠구나 생각하면된다.

Disk 에 파일을 저장하는 방식은 3가지로 나눌 수 있다.
Contiguous Allocation
Linked Allocation
Indexed Allocation
Contiguous부터 알아보자
Disk는 Sector를 나누어 임의적인 크기로 나누어 파일을 저장한다.
밑의 그림을 보면
count 파일은 0,1 이렇게 연속된 구역에 할당된다.


역시나 연속적으로 할당 시에
파일의 크기가 균등하지 않기 때문에 파편화가 발생한다.
또한 파일을 수정을 할 때 파일의 크기가 달라질 수 있는데
위의 경우 count 파일이 length가 7이 되기가 어렵다.
즉, 미리 파일 사이에 공간을 확보해야하는데
공간을 적절히 확보하는 것이 정말 어려운 일이다.
공간이 적으면 파일의 크기가 더 커질 수 없고
공간이 너무 크면 내부 단편화가 발생해 메모리 낭비가 된다.
그래도 빠른 I/O가 가능하다.
Disk에서는 헤드를 이동시킴으로써 접근할 수 있는데
연속적으로 할당된 것의 특성 때문에 시작 sector만 찾으면 빠른 동작이 가능하다.
속도가 빠른 특성 때문에 Swapping 용으로 사용하기도 한다.
Linked Allocation을 알아보자
연결리스트를 공부 많이 했으면
현재 섹터가 다음 sector를 가리키는 포인터가 있는 아래 그림과 비슷하다고 생각할 것이다.
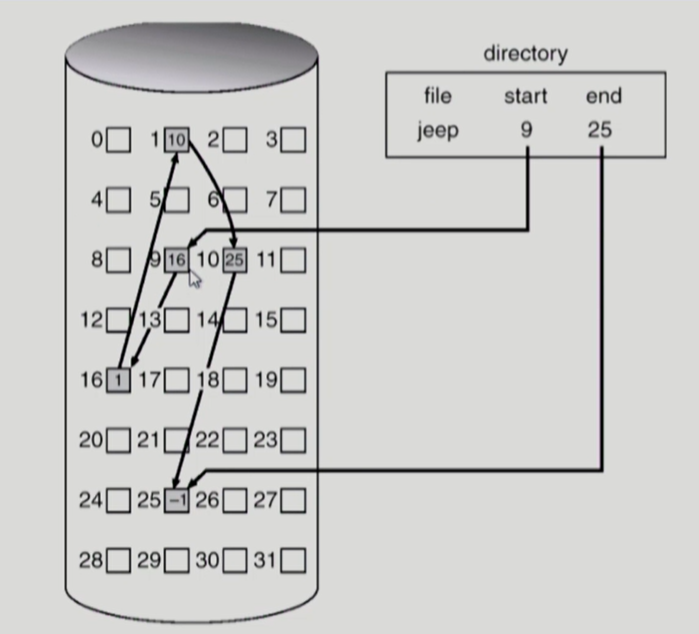

Disk의 Sector의 위치에 아무 상관없이 할당이 가능하기 때문에
파일이 Disk보다 크지만 않다면 외부단편화가 발생하지 않는다.
하지만 임의의 데이터에 접근을 하지 못한다.
또한 이전 섹터에 대해 의존적이기 때문에
섹터가 하나만 고장나도 pointer가 유실될 수 있다.(Reliability)
또한 데이터 외에도 pointer를 가져야하기 때문에 block이 조금 더 커야 한다.
일반적으로 sector는 512B 지만 pointer를 넣어 512B + 4B가 되는 것이다.
FAT라는 것으로 단점을 보완했다.
Indexed Allocation을 보자
파일에 해당 블럭에 위치정보를 담는 것이다.
Linked List와 비슷하면서도 다르다.
즉, 참조해야하는 모든 섹터를 바로 알게된다.


Linked List의 장점과 Contiguous의 장점을 같이 한다고 볼 수 있어서
외부 단편화가 일어나지 않고 임의 접근이 가능하다.
하지만 역시 Trade-off 관계다.
메모리에 대해 낭비가 되겠다.
작은 파일에는 메모리 낭비를
큰 파일에는 index block에 모든 것을 넣을 수 없어서 그렇게 된다.
Linked Scheme, Multi-level index와 같은 방법을 쓴다.
Linked Scheme은 마지막에 다시 다른 Index block을 가리킴으로써 큰 파일에 유연하게 작동 가능하다.
Multi-level도 페이징과 비슷하게
Index block들이 Index block을 가리키는 방식으로 쓰는 것이다.
UNIX 의 파일시스템의 구조다.
아래의 그림을 기본으로 몇 개를 바꾸고 개선하면 현재의 시스템이 되는 것이다.

저렇게 보면
우리가 1TB 하드를 사도 왜 진짜 하드가 1TB를 저장할 수 없는지 이유를 알 수 있다.

우선 DIsk를 4가지 영역으로 나눈다.
Boot 는 당연히 부팅에 필요한 영역이고
영역마다 뭐 설명을 읽어보면 알게 된다.
아래 그림은
FAT File System이다.

boot block은 어느 곳이나 존재한다.
또한 directory가 file의 meta data를 다가지고 있다.
이렇게 포인터로 이어져있는 경우 배드 섹터로 인해 파일이 유실되는 경우가 생길 수도 있다고 했는데
FAT이라는 별도의 공간에 담아서 보관한다.
Data block에 N개의 블럭이 있다면
FAT 는 N-1개의 블럭을 가진다.
FAT는 파일에 구분에 따라 나누어지는 것이 아니라 그냥 다음 블럭을 가리키는 포인터만 존재하는 것이다.
**FAT는 직접 접근이 허용된다.
아래는
단편화 같은 것이 발생했거나 비어있는 block의 경우를 관리하는 방법에 대한 설명이다.

각각의 block에 대해 bit를 더해서 현재 해당 블럭이 쓰였는지를 구분을 할 수 있다.
다른 여러가지 방법도 존재하는데
비어있는 블럭에서도
Linked List를 이용할 수 있다.
하지만 연속적 가용공간을 찾기 어려워서 일반적으로 쓰이진 않는다.

Grouping도 역시나 연속적으로 가용공간을 찾기는 어렵다.
Counting은 직접 세어가며 해당 블럭으로부터 연속적으로 몇개나 비어있나를 알아내는 것이다.
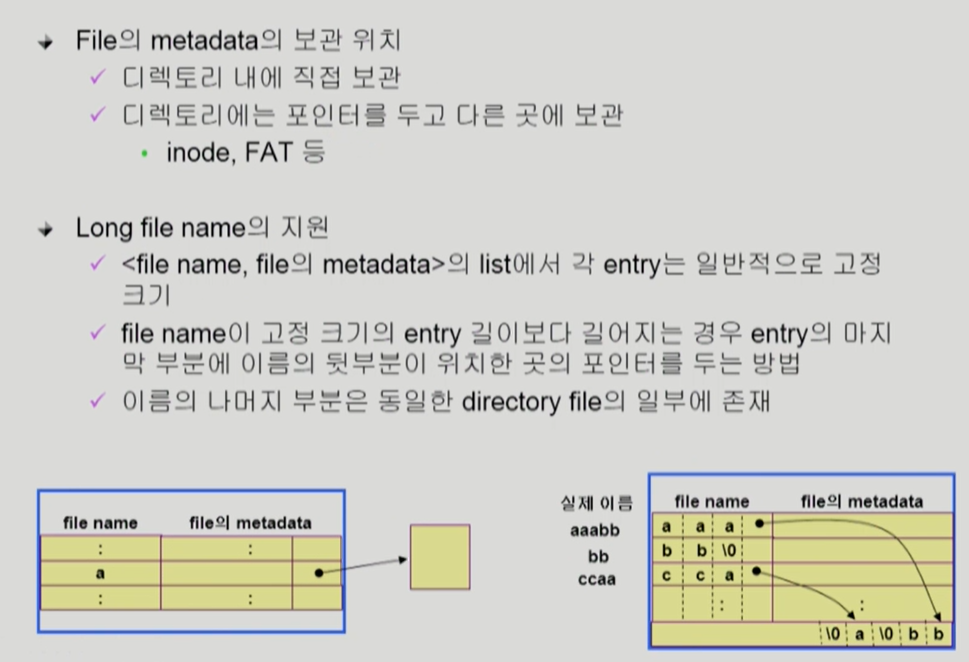
Directory File을 어떻게 이용하느냐..?
아래와 같이 Directory를 관리할 수 있다.

File System도 종류가 여러가지다.
때문에 VFS 인터페이스를 이용하여 다양한 종류의 파일 시스템도 사용자가 문제 없이 이용할 수 있게 한다.
NFS는 역시 네트워크를 이용하는 것이다.
원격에 있는 것도, 로컬에 있는 것도 파일에 접근할 수 있게 하는 것이다.


마지막으로 캐시에 대해서 설명하겠다.

최근에는 페이지 캐시와 버퍼 캐시를 합쳐서 다룬다고 한다.
페이지 캐시에 대해선 페이징을 참고하자.
버퍼 캐시는
파일 입출력 시에 데이터 파일을 읽어온 것을 메모리 영역에 Copy하는 것을 해서 다음 번에 동일 접근 시 빠른 I/O를 제공한다.

그래서 통합된 이후에는
I/O 과정이 조금 달라졌다.

그렇다고 크게 달라진 것은 아니고
그냥 단계가 줄었다 그정도이다.
그래서 파일이 프로그램이 어떻게 실행되느냐?

1. 파일 시스템 안에 파일로 존재하는 프로그램
2. 실행되어 프로세스 생성
3. 프로세스가 자원을 확보하게 되고
4. 바로 쓰이지 않는 데이터의 경우 swap area에서 대기

Data 같은 경우는
당연하게도 수정이 되었으면 Swap area 에다 쫓아내면 다시 접근 할 때
File System에 있는 데이터와 달라지므로 (일관성이 깨짐)
데이터를 물리적 메모리에서 내릴 때는 File System에 쓴다.
'컴퓨터(Computer Science) > 운영체제(Operation System)' 카테고리의 다른 글
| 운영체제 관련 내용 리뉴얼 (0) | 2021.06.27 |
|---|---|
| Disk Management, 디스크 관리 [운영체제] (0) | 2020.06.11 |
| 운영체제에서 스와핑(Swapping) (0) | 2020.06.10 |
| Virtual Memory, 가상메모리 [운영체제] (0) | 2020.06.08 |
| Paging, 페이징, 불연속 메모리 할당 [운영체제] (0) | 2020.06.08 |