이것을 보는 것도 좋겠다.
이 글의 목적은 정확한 개념을 아는 것이고 쉽게 아는 것이다.
Abstraction이랄까. 모든 것을 버리고 중요한 것만 남겨보자
물론 나도 공부 중이라 정확하지 않을 수 있다.
**나오는 용어들
Encoding
Embedding
Similarity
자연어 처리에서 왜 word2vec이 쓰이는가???
자연어 처리라는 것에 대해 간단히 말하고 넘어가자면
"사람들이 말하는 말"을 자연어라고 한다.
그렇다면 처리는 왜하느냐??
흔히 컴퓨터라고 하는 기계는 사람말을 못알아먹는다. 그래서 알아들을 수 있게 처리하는 것이다.
** 여기서 그럼 자연어를 컴퓨터가 알아들을 수 있게 숫자로 표현하려고 하는 방법을 뭐라할까?
Encoding이라고 한다.
그래서 우리는 단어를 숫자에 대응시키고는 한다.
대표적인 Encoding이 One Hot Encoding이라고 한다.

칼로리는 보지 않더라도
사과는 1,0,0
치킨은 0,1,0
브로콜리는 0,0,1로 나온 것을 볼 수 있다.
하지만 위의 3단어를 좌표공간에서 해석해보았을 때 유사도(Similarity)를 알 수 없다.
(Distance가 같음)
**단어에 유사도가 뭐가 필요하냐고?
ㅎㅎ 잘 모르지만 유사도가 없다면 모든 단어는 유추할 수 없을 것 같다.
우리가 모르는 단어도 문맥으로 이해하는 이유는 단어 간에 유사도가 있기 때문이다.
즉, 유사도가 없다면 우린 컴퓨터에게 사용하는 모든 단어들을 알려주어야 하고 문맥마다 알려주어야 한다.
그렇다면 뭐하러 쓰겠나
아무튼 그래서 우리는 다시 Encoding을 넘어선 Embedding을 배워야 한다.
임베딩이란 단어 벡터끼리의 유사도를 구하기 위함이다.
임베딩은 Encoding보다 낮은 차원을 가진다.

이것들처럼
왼쪽의 Encoding이 오른쪽의 좌표평면에 나타낼 수 있게 된다.
Embedding은 유사도를 가지고 있고 가까이 붙어있으면 유사도가 높은 것이다.
다시 말하자면 word2vec은 바로 word embedding이다. 즉 단어를 임베딩하는 것이고
주변의 단어(window)로 유사도를 측정한다. [skipgram에서]
그럼 쉽게 왜 쓴다?
1. 단어를 컴퓨터에게 알아듣게 하려고
2. 그 알아먹은 단어들의 유사도를 컴퓨터에게 알려주려고
그렇다면 word2vec에는 어떤 방법이 있는가?
word2vec 관련 이론 정리
예전에 포스팅한 Kaggle ‘What’s Cooking?’ 대회에서 word2vec 기술을 살짝 응용해서 사용해볼 기회가 있었다. 그 이후에도 word2vec이 쓰일만한 토픽들을 접하면서 이쪽에 대해 공부를 해보다가, 기존�
shuuki4.wordpress.com
위에 글을 참조해도 좋다. 하지만 쉽게 알아보자
1. skipgram 모델
짧게 얘기하자면
주어진 단어 하나로 주위에 몇 단어들의 등장 여부를 유추하는 것이다. 이 때 예측하는 단어들의 경우 ‘가까이 위치해있는 단어일 수록 현재 단어와 관련이 더 많은 단어일 것이다’ 라는 생각을 적용한다.
2. CBOW 모델
주어진 단어 앞 뒤로 N개의 단어를 즉 2N개의 단어를 Input으로 사용하여 주어진 단어를 맞추기 위한 네트워크를 만든다.
사실 둘 다 비슷하다. 더 자세히는 알아보려면 위 글을 참조하자.
어떤 원리로 유사도가 측정되는가???
반복적으로 위 모델을 수행하게 되면 유사도가 나온다.
위 youtube 영상에도 나온다.
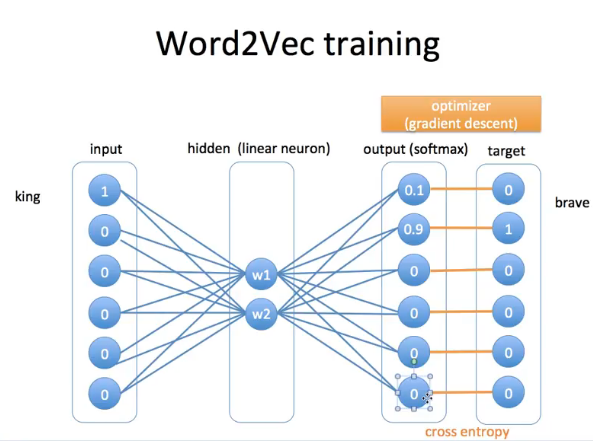
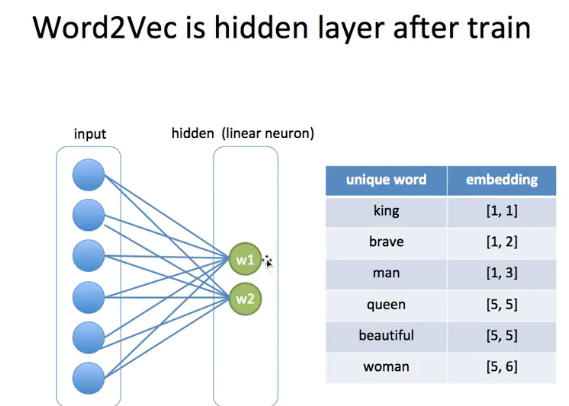
이렇게 임베딩이 되고
컴퓨터는


output을 저렇게 계산해서 알아낸다.
계산은 컴퓨터에게 맡겨라
모델링은 CS전공자에게 맡겨라
공학은 만든 거 잘 쓰자
[데이터 사이언스(Data Science)/자연어 처리 ,NLP] - Word2Vec, Word to vector, 워드투벡터란?
우리는 깊게 이해하기보다 잘 써보자
'데이터 사이언스(Data Science) > 데이터 분석, 자료분석(Data)' 카테고리의 다른 글
| [Python] DataFrame으로 csv파일 만들기, excel만들기 (0) | 2020.08.20 |
|---|---|
| 베이지안 추론이란, Bayesian inference? + 베이지안 분류,Bayesian classification (0) | 2020.08.18 |
| [Data Integration] 데이터 융합이란?(Data Integration) (0) | 2020.08.10 |
| [Python] pandas에서 반복적인 행 접근할 때(Data Processing) (0) | 2020.08.06 |
| [Python] pandas tutorial, 판다스 기본 알아보자 (0) | 2020.07.09 |