** 물리적 저장구조와 인덱스는 뗄레야 뗄 수 없는 조합이므로 같이 배워보자
관계형 데이터 모델에서 데이터베이스는 테이블의 집합이고
테이블은 레코드들의 집합이다.
최종적으로 디스크에 저장되어 관리해야하는데 저장 매체의 관점으로 살펴보는 것이다.
바로 그것이 물리적 저장 구조다.
물리적 데이터베이스는 운영체제가 관리하는 파일 시스템의 기능들을 이용하는데 DBMS 와 파일 시스템과의 관계는
아래 그림과 같다.

** 입출력 단위는 블록(Block)이 된다. -> 우리가 다루는 데이터 수준

블록이란 하나 이상의 레코드들이 저장된 단위를 말한다.
파일이란 하나 이상의 테이블들이 저장된 단위를 말한다.
DBMS는 물리적 저장소가 아니라는 것이다.
도대체 어떻게 블록 내에 레코드를 저장하는 것일까??

이런 SQL문이 있다고 보자. 3가지 레코드를 가지는 테이블이 있다.
어떻게 물리적으로 저장해야할까??

-> 저장하는 블록 방식에 따라 차지하는 용량이 달라진다.
그렇다면 우리는 최대한 작게 용량을 차지하는 것이 좋겠지?? 하지만 꼭 그런 것도아니다.
-> 가변길이를 계산하는 오버헤드도 존재하기 때문 ㅎ, 만약 없으면 다 가변길이로 하지 누가 고정길이로 해!!
저장에 좋은 방법 바로 그 답은
인덱스를 통해 만든다. 염두하고 나가보자.
인덱스는 그렇다면 언제, 왜 만들어야할까??
항상 만드는 것은 아니다. 경우를 한 번 살펴보자
1. 인덱스를 만들면 유리한 경우
-테이블의 레코드 수가 많을 때
-where 절에 자주 사용될 필드, 칼럼
-join(조인) 연산에 참여하거나 NULL이 많은 필드
2. 인덱스를 만들면 불리한 경우
-테이블의 레코드 수가 적을 때
- where 절에 거의 사용되지 않는 필드
-CRUD가 자주 발생하는 테이블
- 서로 구별되는 유일 값의 개수가 적은 필드(성별 같은 경우 2가지)
즉 1번에 해당하면 인덱스 만들고 2번에 해당하면 만들지 말란소리다.
그리고 책을 꽂을 때를 생각해보자
우리가 책을 크기대로 꽂는 생각이 나지?
그래서 우리는 이렇게 크기든 뭐든 기준을 나누어서 꽂는다. DB에도 그런 것이 필요하지 않을까?
그래서 클러스터링(Clustering)이란 것이 생겼다.

만약 우리가 책의 크기로만 책을 꽂는다면 다시 그 책들 속에서는 어떻게 골라낼까??
그래서 우리는 또 필요로 한다.
바로 인덱스(index)를
왜?
파일 내 레코드의 위치를 빨리 찾긱 위해, 없다면 순차검색을 해야함.

데이터베이스의 인덱스는 실제로 레코드에 대한 물리적 저장위치를 별도로 기록하는 것이다.
인덱스의 구조를 보자
- 인덱스 엔트리 : (검색키, 주소)
- 검색키 : 테이블에ㅡ 속한 한 개 이상의 필드
?? 그럼 인덱스를 어떻게 만드는데???? (++ 삭제는 어떻게하고??)
밑의 자료들을 보고 가자


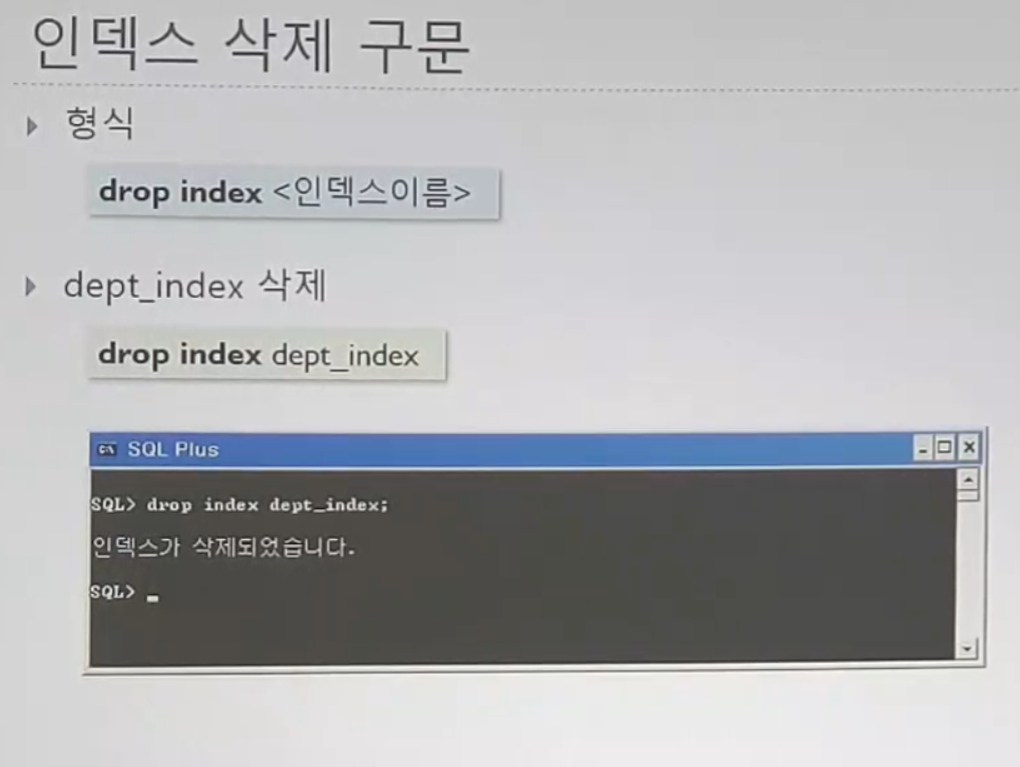
필요한 이유를 여기서 다시 느껴보자

다시 몸소 느껴보자


그래서 인덱스를 무엇으로 해야하는데..??
우선 우리는 디폴트로 기본키를 인덱스를 생성한다.
왜? -> 레코드의 검색, 삽입, 삭제시 빈번하게 조회되는 값이 바로 기본키이다.
인덱스로 얻는 장점
-검색 속도 향상
단점
-테이블에 레코드를 삽입하고 관련 정보를 인덱스에 갱신해야함
-인덱스가 많아지면 CRUD 연산 속도 저하
관계형 데이터 베이스 (RDBMS)에서 인덱스로 자주 사용되는 자료구조라고
B+ 트리라는 것이 있다.
안 보고 갈 수는 없지 맛만 보자


실제론 어떻게 된다는 말일까??

뭐 진짜 트리구조이다. 별 거 없다.

근데 이렇게 얻는 장점이 뭐냐? 당연히 서치(검색)속도가 빨라진다.
인덱스를 배웠으니 더 진화된 개념인 복합 인덱스(Compoiste index)에 대해서 맛만 보고 가자.

이렇게 생겼다.
두 개 이상의 필드에 대해 하나의 인덱스를 생성하는 것이다.
++ 엔트리들은 검색키 값의 순서대로 정렬된다.

복합 인덱스의 장점으로는...? 더 잘찾음 ㅎ 당연히 조건이 더 붙어있으니까?

하지만 주의사항도 있으니.. 한 번 보고가자

++++참고사항으로 엔트리 정렬에 대해 알아보자면... 숫자면 오름차순, 내림차순
문자열이면 사전순, 사전역순이 있다고 알아두고 가자.

다음으로는 해시 인덱스(hash index)이다.
++해시는... key,value를 생각하면 되겠다.
해시 함수를 기반으로 인덱스 엔트리를 구성한다. 각 엔트리들은 버켓으로 구분된다.
버켓(bucket): 인덱스 엔트리가 저장되는 공간이면서 버켓 번호는 해시 함수의 값이 된다.

해시라는 자료구조를 안다면 사용방법이야 쉬울 것이다. 하지만 모르는 사람을 위해서 복습해보자
인덱스 구성방법은
-인덱스 구성에 사용될 필드 결정
-필드 값에 해시 함수를 적용하여 버켓 번호를 생성
-인덱스 엔트리를 생성하여 해당 버켓에 저장
인덱스 사용방법은
- 검색할 값을 해시 함수에 적용하여 버켓번호 생성
- 해당 버켓 안에 들어있는 인덱스 엔트리 검색
-> 위의 방법 또한 검색속도가 빨라진다.
** 해시함수의 정의도 보고가자.

마지막은 역시 예를 통해 익혀야겠지??

** 해싱의 가장 큰 특징이 있다!! 알고 가자.

해싱을 이용한 방법에는 버켓의 크기가 만약 정해져 있다면 오버플로우(overflow)라는 것이 발생할 수 있다.
물론 해시 함수를 되도록 균등하게 짜겠지만... 그런 경우가 발생할 수 있다.
이렇게 많은 방법이 있다. 어느 것이 유리할까??
당연히 한 방법만 계속 유리하진 않을 것이다.
사용 목적, 저장 방식 모든 것에 따라 결정날 것인데.. 일반적인 경우를 살펴보면??

그냥 그렇게 알고만 가자. 어느 한 쪽이 항상 좋을수는 없다.
마지막으로 인덱스의 종류에 대해서 알아보자
그 인덱스의 끝이 보인다.
1. 희소 인덱스,(sparse index) (나중에 데이터를 다룰 때 요긴하게 쓰인다)
- 테이블의 일부 레코드에 대해서만 인덱스 엔트리를 생성
2. 밀집 인덱스(dense index)
-테이블의 모든 레코드에 대해서 인덱스 엔트리를 생성

3. 클러스터 인덱스(clustered index)
-인덱스 엔트리 순서대로 레코드 저장
4. 비클러스터 인덱스(non-clustered index)
-인덱스 엔트리 순서와 상관없이 레코드 저장

'컴퓨터(Computer Science) > 데이터베이스, DB, DataBase' 카테고리의 다른 글
| 데이터베이스, 트랜잭션(Transaction) -2(동시성 제어) (0) | 2020.12.14 |
|---|---|
| 데이터베이스, 트랜잭션(Transaction) -1 (개념과 정의) (0) | 2020.12.14 |
| 데이터베이스의 논리적 설계~최종 테이블 스키마 (0) | 2020.12.13 |
| 데이터베이스의 개념적설계(Conceptual Design) (5) | 2020.12.13 |
| 데이터베이스의 설계( Database Design) (0) | 2020.12.13 |