구글에서 발표한 딥러닝 아키텍쳐다.
말 그대로 아키텍쳐이다. 얘 스스로는 아무것도 아니고 어떻게 이용하느냐에 따라 달라진다.
근데 자연어처리(NLP)측면에서는 트랜스포머의 등장이 획기적인 성능 향상을 가져왔다고 볼 수 있다.
**하지만 트랜스포머의 이해를 위해서는 S2S, Sequence to Sequence의 개념을 먼저 아는 것이 필요하다.
++ Attention 메커니즘에 관한 이해도 필요하다.
Sequence to Sequence (S2S) 시퀀스 투 시퀀스란?
안다면 이제부터 설명해보겠다.
기존의 Seq to Seq 모델의 한계를 Attention이 보정해주었다.
RNN의 한계를 보정한 것인데..?
RNN이 아닌 Attention을 활용할 수 있는 새로운 네트워크를 만들면 어떨까??? 라는 생각에서 나왔다.
그렇게 되면 시퀀스의 길이에 따라 계산량이 많아지는 단점도 개선할 수 있지 않을까??
그렇게 해서 Attention is All you need 라는 논문이 나왔다.

기본적인 트랜스포머의 구조다.
?? 어텐션은 인코더랑 디코더 뭐 어쩌고 저쩌고 아니었나??
Input(왼쪽)이 인코더, Output(오른쪽)이 디코더와 대응한다.
++ RNN CELL로 입력이 2개가 있었는데 트랜스포머 구조는 조금 다르다.

seq2seq 구조에서는 인코더와 디코더에서 각각 하나의 RNN이 t개의 시점(time-step)을 가지는 구조였다면
이번에는 인코더와 디코더라는 단위가 N개로 구성되는 구조다.
요렇게

설명에 앞서 하이퍼파라미터를 보자.
보면 모델에 대해 조금 더 잘 알 수 있고 내가 무엇을 조정해야 성능이 올라갈지 알 수 있다.

대표적인 하이퍼 파라미터다.
보면..
인코더 디코더의 벡터의 크기에 따라..성능이 차이가 심할 것 같기도 하고
인코더 디코더가 몇 개의 layer를 가질지도 정해야하구.
병렬수행되면 속도가 빠르겠구나 싶고
내부 히든레이어 갯수도 중요하구나 싶고 정말 옵션이 많네..
하기싫다 ㅋㅋㅋㅋㅋ
가 아니라 더 알아보도록 하자.
그럼 다시... 인코더랑 디코더를 이용해 트랜스포머 구조를 다시 보면..?

인코더가 입력을 받아서 디코더가 출력 결과를 만들어내는 구조를 볼 수 있다.
RNN 이 사용되지는 않았지만 Seq2Seq랑 비슷하게 생겼다.
비슷해보이지만 다른 것이 있다!!
바로 트랜스포머가 입력받을 때 약간 다르게 받는다.
Positional Encoding이라고 하는데 RNN의 사용 목적인 시퀀스, 즉 순서 정보를 얻을 수 있기 때문에 그러한 한계를 감수하고 쓴 것이다.
그래서 그 순서정보를 이 구조에서도 얻을 수 있게 한 것이 바로 포지셔널 인코딩이다.
(병렬적으로 입력받기 때문에 순서정보를 알 수 없으니 positional endoing을 통해 위치 정보를 주는 것이다)

입력으로 사용되는 임베딩 벡터들이 입력으로 사용 되기 전에 Positional Endoing에 더해져서 위치 정보를 갖게 된다.
??? 뭐가 더해지는겨??
사실 위 그림을 보면 정확히 감이 안 온다. 그래서 다시 가져왔다.

색을 보면 위치에 따라 색이 달라지는 것을 알 수 있다. 이것들이 위치 정보다.
??근데 Positional Encoding 값은 어떻게 만드는거야?? 이미 만들어져있나??
포지셔널 인코딩 값을 만들기 위해 2가지 함수를 사용하는데...?
알고만 넘어가자.
PE -> Positional Encoding

각 임베딩 벡터에 PE값을 더하면 같은 단어라도 위치에 따라서 트랜스포머의 입력으로 들어가는 임베딩 벡터의 값이 달라지게 된다.
즉, 위와 같은 함수를 통해서 시퀀스 모델을 사용하지 않아도, RNN이 아니어도
위치 정보를 가지고 연산할 수 있게 된다.
그렇구나..? 인코더 디코더는 조금 알겠다.
근데 어디에 어텐션이 사용된 거지???
그 전에!! 우선 기억나나.. 어텐션 함수의 Q,K,V?
Query, Key, Value가 트랜스포머 모델에서도 쓰인다. 하지만 그 Q,K,V는 트랜스포머에 맞게 바뀌었다.
이것은 Self-Attention 개념을 적용한 것이다. Q=K=V
**자연어 처리 과정에서
Q: 입력 문장의 모든 단어 벡터
K: 입력 문장의 모든 단어 벡터
V: 입력 문장의 모든 단어 벡터
-> 같다는 의미는 같은 벡터에서 나오는 것이라는 의미지 값이 같다는 것이 아니다.
기존의 어텐션이 디코더와 인코더를 통해 다른 문장 간의 유사도을 파악했다면
Self-Attention은 입력 문장의 단어들 사이의 유사도를 얻을 수 있다.
다시.. 어텐션이 어디 사용되는 거지???
위에 self-attention이 사용되었고...?
그걸 포함해서 트랜스포머에서는 3가지 어텐션이 사용된다.

다시 정리하면
인코더의 셀프 어텐션 : Query = Key = Value
디코더의 마스크드 셀프 어텐션 : Query = Key = Value
디코더의 인코더-디코더 어텐션 : Query : 디코더 벡터 / Key = Value : 인코더 벡터
아니 어텐션이 쓰이는 것은 알겠는데 어디 쓰이냐고...???

그래서 그림 가져옴. 이렇게 3군데에서 쓰이네~
**FF가 Feed Forward 약자임
그럼 다시.. 어텐션이 어디 쓰이는 지 알았고 어떤 어텐션이 쓰이는 지 알았으면 하나하나씩 다시 살펴봐야지?
인코더에서의 Self-Attention을 알아보자
앞서 말했듯이 셀프 어텐션은 Q=K=V가 되는 어텐션이다.
근데 왜 Self-Attention을 적용했느냐??
무엇을 위해???

이 그림을 보자.
위의 예시 문장을 번역하면 '그 동물은 길을 건너지 않았다. 왜냐하면 그것은 너무 피곤하였기 때문이다.' 라는 의미가 된다. 그런데 여기서 그것(it)에 해당하는 것은 과연 길(street)일까? 동물(animal)일까?
누구나 이 글을 보면 피곤한 주체가 동물이라는 것을 아주 쉽게 알 수 있지만 기계는 그렇지 않다.
하지만 셀프 어텐션은 입력 문장 내의 단어들끼리 유사도를 구하므로서 그것(it)이 동물(animal)과 연관되었을 확률이 높다는 것을 찾아낸다.
++ 어떻게?? 는 나중에 각자 알아보자 ㅎㅎ
그래서 Q,K,V는 어떻게 찾는데?
어떻게를 이해하는 것은 어렵다... 내가 참고한 사이트에 따르면..
셀프 어텐션은 인코더의 초기 입력인 d의 차원을 가지는 단어벡터들로부터
Q,K,V 벡터를 얻는다. (가중치 행렬을 곱함으로써 얻을 수 있다.)

자세히는 각자 알아보자
Q,K,V 벡터를 얻었으니 써먹어야지??Q 벡터는 모든 K 벡터에 대해서 어텐션 스코어를 구하고그후 어텐션 분포를 구한 뒤 V 벡터와 가중합 하여 context vector를 만들고 이를 반복한다.
앞서 말한 어텐션 중Scaled Dot-Product Attention이 활용되는데 ++Dot-product attention에서 값을 스케일링하는 것을 추가한 것이다.
입력은 입력 문장의 단어수 * 입력 임베딩 차원의 수 로 행렬 형태를 가진다. 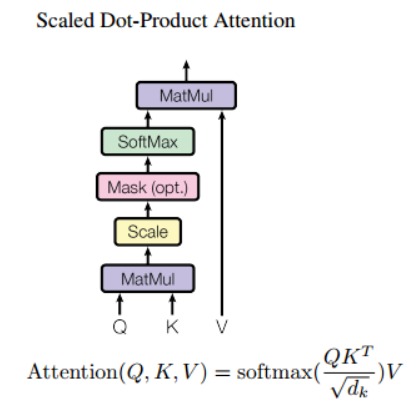
입력 행렬에 Q, K의 가중치를 곱해 계산한다. 그래서 Q와 K가 얼마나 관련이 있는지 내적하고 이를 키 벡터의 차원수의 제곱근을 나누어준 뒤 softmax를 하고확률값을 가중치삼아 가중합을 만든다.
사실 수식적으로 이해하면 좋지만 몰라도 상관없다. 사실 dot-product는 코사인 유사도의 작업 중 하나라고 할 수 있다.때문에 어떤 Q,K가 중요하다면 트랜스포머 블록을 이용해 내적 값을 키우는 방향으로 학습한다.
**이 어텐션의 특징은 트랜스포머에서 입력 단어 벡터를 바로 적용하는 것이 아니라 작은 차원의 벡터로 만드는 것에 있다.
나는 고수준의 이해까지 하기 싫다. 다른 것 하고 싶어!! ㅎ그래서 다음 어텐션으로 넘어가자
Multi-Head Attention이다.
얘도 또한 입력 매트릭스와 출력 매트릭스의 크기는 입력 단어 수 * 히든 벡터 차원 수로 동일하다.

단어 임베딩 벡터로 나온 Q,K,V로 어텐션 수행을 하는 것 보다 다른 매트릭스들을 곱하여 어텐션 결과를 얻고
이른 concat(접합) 시켜서 가중합을 구해 어텐션 값을 만드는 것을 목적으로 한다.
-> 단순히 말하면 Scaled-Dot-Product Attention을 여러번 수행함을 말한다.
**트랜스포머 연구진은 한 번의 어텐션을 하는 것보다 여러번의 어텐션을 병렬로 사용하는 것이 더 효과적이라고 판단해서 이런 방법이 나왔단다.
병렬적으로 어텐션 했기 때문에 여러가지 머리가 있다고 말한단다.

이런 방법으로 구현한다고 한다.
- WQ, WK, WV에 해당하는 d_model 크기의 밀집층(Dense layer)을 지나게한다.
- 지정된 헤드 수(num_heads)만큼 나눈다(split).
- 스케일드 닷 프로덕트 어텐션.
- 나눠졌던 헤드들을 연결(concatenatetion)한다.
- WO에 해당하는 밀집층을 지나게 한다.
이것도 여기까지만... ㅎㅎ
다음으로는 Position-wise FFNN이라는 것인데
포지션 와이즈 FFNN은 인코더와 디코더에서 공통적으로 가지고 있는 서브층(sub layer)이다.
사실 Fully connected feed-forward 가 수행되지만 개별 단어마다 적용된다고 해서 position-wise가 붙었다.

음 다른 그림을 보면 더 잘 이해될수도?

두 번의 선형 결합과 중간에 relu함수를 활성화 함수로 적용했다.
음.. 왜 저렇게 했을까? 를 이해하는 것은 쉽지 않은 일이다.
참고
'데이터 사이언스(Data Science) > 자연어 처리 ,NLP' 카테고리의 다른 글
| 딥러닝 챗봇 만들기 - 4 (실제 프로젝트 만들어보기) (0) | 2021.01.16 |
|---|---|
| 딥러닝 챗봇 만들기 - 3 (파이썬 이용하기) (0) | 2021.01.10 |
| Attention, 어텐션 메커니즘 (0) | 2021.01.08 |
| 자연어 처리에서의 용어 (0) | 2021.01.07 |
| Sequence to Sequence (S2S) 시퀀스 투 시퀀스란? (0) | 2021.01.07 |