앞서 나온 자료구조보다 해시 테이블은 비교적 빠른 탐색 속도를 가지고 있다.
어떻게 그렇게 될 수 있는지 알아보고
어떤 자료를 표현하기에 적합한지 생각해보자
또한 여기선 lookup 이라는 용어를 알 수 있다.
lookup은 조회로 해석되는데
특정 원소가 컨테이너에 있는지 확인하거나 컨테이너 키 값에 해당하는 value를 찾는 작업을 말한다.
단적으로 배열에선.. 어떠한 것이 있는지 알려면 O(N)의 시간이 걸린다.
왜냐하면 모든 것을 살펴봐야 하기 때문이다.
그렇다면 얘는 어떤 방식이길래 그것보다 빠를 수 있을지 생각해보자
앞서 배운 이진 탐색을 생각했다면 똑똑한 사람이다.
[문제풀이(Problem Solving)/C++ 문제풀이에 유용한 것들] - 이진탐색, Binary Search
하지만 여기서 알아볼 자로구조는 해시 테이블이다.
어떻게 쓰는지 알아보자
우선 이진탐색이 빠르다고 생각했다면 영어사전을 생각해보자
영어 사전에는 수십만 단어가 있고 BST의 속성을 갖도록 균형트리에 저장하여
O(log N)의 검색속도를 가진다고 하자. 뭐야 빠르네~
**근데 난 숫자가 아닌 BST는 모르겠는데..? 뒤에서 설명하겠다.
물론 이진탐색도 빠르지만 어떻게 해야 더 빠르게 검색할 수 있을까 해서 나온 것이 해시테이블이다.
해싱, Hashing을 이용해서 각 데이터를 저장하는 것으로
해싱은 해싱 함수를 이용해 어떠한 값을 고유한 숫자값으로 바꾸어 표현하는 것을 말한다.
0부터 10억까지의 숫자가 무작위로 주어진다고하자.
우리는 0부터 10억까지의 숫자 중 어떤 것이 몇개 있는지 알고싶다. (lookup)
그렇다면
10억의 크기를 가진 배열을 만들고
해당 숫자가 나올 때마다 해당 배열의 원소 값을 +1 해주면 된다.
간단하지??
근데 정말 10억짜리 배열을 만드는 것이 괜찮을까?
우선 int 형 데이터는 32bit, 4byte의 크기를 가진다.
어림잡아 계산해서 40억byte라는 4GB 가 필요하다.
??? 이게 가당키나 한 메모리 사용량인가??
절대 아니다.
위에선 데이터 범위가 너무 커서 문제가 되었다.
또한 우리는 숫자가 아닌 BST를 알지도 못한다.
즉, 데이터가 숫자가 아니거나, 숫자가 아니어도 실수인 경우, 데이터 범위가 너무 큰 경우 해당한다.
우리는 어떻게 lookup을 해야할 지 고민이 된다.
** 문자열의 경우 문자하나하나 아스키코드 값으로 더할 수 있지만 충돌이 많이 발생한다.
그래서 이 문제를 해결하기 위헤 어떤 데이터 타입의 값도 고유의 숫자로 만들어주는 함수를 만들어 사용하기로 하였다.
그것이 바로 해시 함수이다.
우리는 이러한 함수를 간단하게 modulo 로 두고 알아보겠다.
모듈러는 나머지 연산을 뜻한다.
즉, 모듈러가 17이라면 어떠한 데이터에 해시함수를 적용했을 때 나올 수 있는 값은 0-16 밖에 없다는 뜻이다.
물론 여기서 7과 24가 해시함수를 거쳤을 때 같은 값을 가지게 되어 Collision, 충돌이 발생하게 되는데
이는 뒤에서 처리하기로 하자.
아래 그림을 보면 해시함수가 모듈러 7인 것을 알 수 있다.

하지만 여기선 딱 봐도 Collision이 발생하면 이전에 저장되어 있던 값이 사라질 느낌이다.
맞다.
메모리를 아껴서 찾는 것은 좋았는데
충돌 시에 해결 방법을 찾아야 써먹을 수 있겠다.
사람들은 그래왔듯이 답을 찾았다.
1. 체이닝, Chaining
체이닝은 충돌 시 하나의 공간 밖에 없어 이전의 결과가 지워지는 불상사를 막기 위해
충돌이 되더라도 해당 값도 저장하는 방식을 의미한다.
즉, 해당 결과 뒤에 연결 리스트를 하나 추가시킨다고 생각하면 된다.
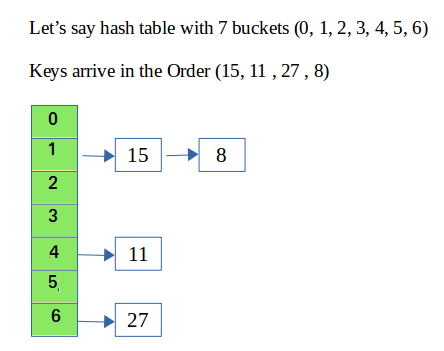
일단 삽입에 대해선 맨 뒤에 추가시키기에 O(1)의 시간이지만
정말 해당 값을 찾고자 한다면
해당 연결리스트를 다뒤져야하는 사태가 발생할 수 있다.
더군다나 Hash function을 잘못 설정하면
해당 key 값에만 value들이 몰릴 수 있어서 그냥 연결리스트로 저장하는 꼴이 될 수 있어서
Hash function을 잘 설정하는 것이 체이닝의 핵심이다.
2. 열린 주소 지정, open addressing
이 방법도 이전의 결과를 버리지 않고 저장하는데
리스트를 붙여서 저장하는 방식이 아니라
모든 원소를 해시 테이블 내부에 저장하는 방식이다.
때문에 테이블의 크기가 반드시 데이터의 개수보다 커야 한다.
즉, 해당 key 값을 가지더라도 다른 key 값에 저장이 되는 방식이다.
다른 테이블을 찾을 때는 여러가지 방법이 있다.
단적인 예를 들어 x+1의 위치를 확인하는 방법이다.

100은 2의 위치에 있는 공간에 들어가야하지만 이미 차있기에 다른 셀을 찾는다.
이 방법도
Hash function에 의존성이 큰데
Collision이 많이 발생할수록 이러한 방법의 성능이 떨어질 수 밖에 없는 것을 알 수 있다.
즉, 해당 테이블 주변에 Clustering, 군집화가 생겨서 성능이 떨어지게 된다.
역시 해시함수가 중요하다.
3. 뻐꾸기 해싱, Cuckoo hasing
이론적으로 완벽한 해싱 기법 중 하나다.
최악의 상황에서도 O(1)의 시간복잡도를 구현할 수 있다.
뻐꾸기 해싱은 크기가 같은 2개의 해시 테이블을 사용하고
각각의 해시 테이블은 다른 해시 함수를 가지게 한다.
모든 원소는 두 해시 테이블 중 하나에만 있을 수 있으며 그 위치는 해당 해시 테이블의 해시 함수에 의해 결정된다.
즉, 원소가 두 해시 테이블 중 어디든 저장이 가능하고
원소가 나중에 다른 위치로도 이동할 수 있다.
예를 들어
lookup을 시행하는 경우
특정 원소의 존재를 위해 저장 가능한 위치 2 군데만 확인하면 된다.
하지만 삽입은 조금 더 시간이 걸린다. (역시 trade-off)
원소 A를 넣는다고 생각해보자

첫 번째 해시 테이블에서 A를 삽입할 수 있나 본다.
B가 이미 존재한다.
그렇게 되면
B를 2번째 테이블로 옮기고
해당 위치에 A를 넣는다.
?? 근데 B를 넣어야 할 위치에 또 C가 있네
그렇다면
C를 다른 테이블에 옮기고
B를 C의 위치에 넣는다.
이러한 작업을 재귀적으로 하여 완전히 비어서 온전히 할당될 때 까지 지속한다.

하지만 위와 같이 순환이 발생하는 경우 재귀적으로 수행이 멈추지 않는 무한 루프에 빠지게 된다.
순환이 발생하면 새로운 해시 함수를 이용하여 재해싱해야하는 경우가 생긴다.
역시 이것도 해시함수를 잘 짜야 제대로 작동할 수 있다.
다행히 C++에서는 해시에 대한 컨테이너를 제공한다.
map이라는 STL이다.
아래 글에서 알아보자
[프로그래밍언어(Programming Language)/C || C++] - STL 맵, map 사용법 [C++]
'문제풀이(Problem Solving) > C++ 문제풀이에 유용한 것들' 카테고리의 다른 글
| MST, 최소 신장 트리 [CPP] (0) | 2021.07.06 |
|---|---|
| 각 유용한 함수들 [CPP] (0) | 2021.07.05 |
| Graph, 그래프 , 자료구조 [CPP] (0) | 2021.07.05 |
| C++ 코딩테스트에 유용한 것들 [CPP] (0) | 2021.06.18 |
| 이진탐색, Binary Search (0) | 2021.06.18 |