DB 공부를 소홀히 했었다.
솔직히 내가 슬로우쿼리를 엄청나게 개선시킬 자신은 없지만 DB와 작업이 어떻게 되는지는 알아야 한다.
그래서 DB를 공부하기로 했다.
알아보자
DB 파티셔닝이 무엇인지부터 알아보자
파티셔닝이란 논리적인 데이터 element들을 다수의 entity로 쪼개는 행위 라고 한다.
즉, 한 덩어리로 있어도 되는 것들을 쪼개는 행위다.
DB 입장에서 말하자면
큰 table이나 index를, 관리하기 쉬운 partition이라는 작은 단위로 물리적으로 분할하는 것을 의미한다.
**물리적인 데이터 분할이 있더라도, DB에 접근하는 application의 입장에서는 blackbox 이다.
=> 알 수 없어야 한다.
??? 음.. 왜 필요한데???
서비스의 크기가 점점 커지고 DB에 저장하는 데이터의 규모가 커졌다.
예를 들면 게임의 경우 모든 유저의 정보를 하나의 VLDB(Very Large DBMS)가 갖기는 힘들어졌다.
하나가 전부를 가진다면 성능도 안나오고 관리도 어려워질 것이다.
다시 말하면 기존에 사용하는 DB storage의 한계와 performance의 저하라는 과제를 해결해야 했다.
이런 이슈를 해결하기 위한 방법으로 table을 ‘파티션(partition)’이라는 작은 단위로 나누어 관리하는
‘Partitioning’이 나타나게 되었다.
‘Partitioning’을 통해
소프트웨어적으로 데이터베이스를 분산 처리하여 성능이 저하되는 것을 방지하고 관리를 쉽게 할 수 있다.
아하.. 그렇구나
어떤 방식으로 도움이 된다는 거지..?
3가지 측면에서 도움이 된다.
Performance - 성능
주로 대용량 Data WRITE 환경에서 효율적이다.
필요한 Partition만 Main Memory에 load 함으로서 효율적인 Memory사용이 가능
데이터 전체 검색 시 필요한 부분만 탐색해 성능이 증가한다.
불필요한 Partition에 대한 Access가 지양 ( Partition Pruning )
즉, Full Scan에서 데이터 Access의 범위를 줄여 성능 향상을 가져온다.
Sort 작업 시 물리적 Temporary Segment 사용의 최소화 로 인한 수행속도 향상
많은 INSERT가 있는 OLTP 시스템에서 INSERT 작업을 작은 단위인 partition들로 분산시켜 경합을 줄인다.
Manageability - 관리하기 쉬움
앞서 말했듯이 엄청 큰 테이블을 나눠버린다.
테이블을 나눔으로써 관리하기 쉽게 만든다.
Availability - 가용성
물리적으로 나눔으로써 전체 데이터가 손상되는 위험을 줄이고 데이터 자체의 가용성을 늘릴 수 있다.
또한 물리적으로 나누어져 있기 때문에 독립적으로 백업과 복구가 가능하다.
Partition된 테이블들의 크기가 작아졌으므로 I/O를 분산하기 때문에 UPDATE 성능이 향상된다.
아니 진짜 좋은데??? 근데 항상 Trade-Off 관계일텐데 좋기만 할 수는 없지
단점이 뭔데???
단점
table간 JOIN에 대한 비용이 증가한다.
table과 index를 별도로 파티셔닝할 수 없다.
테이블과 인덱스를 별도로 파티션 할수는 없다.
테이블과 인덱스를 같이 Partitioning 하여야 한다.
table과 index를 같이 파티셔닝해야 한다.
그렇다하더라도...?
크면 마냥 파티셔닝을 할 수는 없잖아..?
어떤 방식으로 파티셔닝을 하는거야?
어떤 기준으로 하는거야?
먼저 방식부터 알아보자
여러가지 방식이 있다.
1. Horizontal
하나의 테이블의 각 행을 다른 테이블에 분산시키는 것
**샤딩이랑 같음
**일반적으로 분산 저장 기술에서 파티셔닝은 수평 분할을 의미

스키마 복제 후, 샤드 키를 기준으로 데이터를 나눔
=> 스키마가 같은 데이터를 테이블 여러개로 나누는 것임
장점
대부분 샤딩을 사용하는 것은 데이터의 개수를 기준으로 사용한다.
데이터의 개수가 작아지고 따라서 index의 개수도 작아지게 된다.
자연스럽게 성능은 향상된다.
단점
서버간의 연결과정이 많아진다.
데이터를 찾는 과정이 기존보다 복잡하기 때문에 latency가 증가하게 된다.
하나의 서버가 고장나게 되면 데이터의 무결성이 깨질 수 있다.
2.Vertical
하나의 엔티티에 저장된 데이터를 2개 이상의 엔티티로 분리하는 것이다.
**여기선 스키마가 달라진다.
CustomerId로 참조하고 테이블을 나눌 수도 있다는 것이다.
장점
자주 사용하는 컬럼 등을 분리시켜 성능을 향상시킬 수 있다.
한 테이블을 SELECT하면 결국 모든 컬럼을 메모리에 올리게 되므로 필요없는 컬럼까지 올라가서 한 번에 읽을 수 있는 ROW가 줄어든다.
이는 I/O 측면에서 봤을 때 필요한 컬럼만 올리면 훨씬 많은 수의 ROW를 메모리에 올릴 수 있으니 성능상의 이점이 있다.
같은 타입의 데이터가 저장되기 때문에 저장 시 데이터 압축률을 높일 수 있다.
다음은 기준이다.
파티셔닝을 어떤 기준에 의해서 하는 것일까??
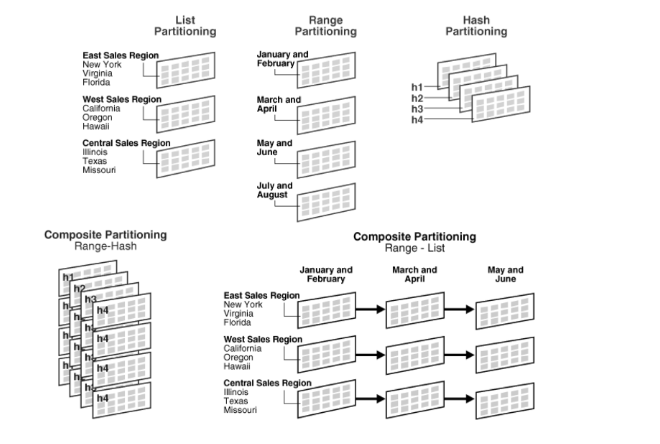
1. 범위 분할 (range partitioning)
분할 키 값이 범위 내에 있는지 여부로 구분한다.
예를 들어, 우편 번호를 분할 키로 수평 분할하는 경우이다.
2. 목록 분할 (list partitioning)
값 목록에 파티션을 할당 분할 키 값을 그 목록에 비추어 파티션을 선택한다.
예를 들어, Country 라는 컬럼의 값이 Iceland , Norway , Sweden , Finland , Denmark 중 하나에 있는 행을 빼낼 때 북유럽 국가 파티션을 구축 할 수 있다.
3. 해시 분할 (hash partitioning)
해시 함수의 값에 따라 파티션에 포함할지 여부를 결정한다.
예를 들어, 4개의 파티션으로 분할하는 경우 해시 함수는 0-3의 정수를 돌려준다.
4. 합성 분할 (composite partitioning)
상기 기술을 결합하는 것을 의미하며, 예를 들면 먼저 범위 분할하고, 다음에 해시 분할 하는 것
컨시스턴트 해시법은 해시 분할 및 목록 분할의 합성으로 간주 될 수 있고 키 공간을 해시 축소함으로써 일람할 수 있게 한다.
참고링크
http://wiki.gurubee.net/pages/viewpage.action?pageId=3899999
https://www.quora.com/Whats-the-difference-between-sharding-DB-tables-and-partitioning-them
http://theeye.pe.kr/archives/1917
https://en.wikipedia.org/wiki/Partition_(database)
https://gmlwjd9405.github.io/2018/09/24/db-partitioning.html
'컴퓨터(Computer Science) > 데이터베이스, DB, DataBase' 카테고리의 다른 글
| Index, 인덱스 (0) | 2022.12.01 |
|---|---|
| Key, 키 (0) | 2022.12.01 |
| 데이터베이스, 트랜잭션(Transaction) - 3(장애와 복구) (0) | 2020.12.14 |
| 데이터베이스, 트랜잭션(Transaction) -2(동시성 제어) (0) | 2020.12.14 |
| 데이터베이스, 트랜잭션(Transaction) -1 (개념과 정의) (0) | 2020.12.14 |