캐시 메모리에 대해서 이어나가보자
이번에는 캐시 메모리가 어떻게 작동을 하는지 원리를 알아보겠다.

즉, Xn이 없다가 생긴 것을 보여준다.
캐시로 Xn을 올린 것인데
여기서 3가지 의문점이 들어야한다.
0. 해당 데이터가 캐시에 들어있는지 어떻게 찾는거지?
1. 없다면 해당 데이터를 어떻게 찾는거지? (즉, 답하자면 하위레벨에서 다시 찾는다.)
2. 해당 데이터를 어떻게 다른 빈칸도 아니고 저 빈칸에 놓는거지?
사실 제일 간단한 방법은
**메모리의 각 워드에 캐시 내의 위치를 할당하는
즉, 메모리 주소에 기반을 두고 할당하는 "직접 사상( direct mapping)" 이다.
** 메모리 위치는 캐시 내의 딱 한 장소에 직접 사상된다.
물론 다른 방법도 있다.
사실 캐시를 사용하기 위해 필요한 비트 수는 각각 다르다.
하지만 아래 조건이라고 가정하자면
1. 32비트의 주소
2. 직접 사상 캐시
3. 캐시는 2^n개의 블록을 가지고 n개의 비트는 인덱스를 위해 사용
4. 캐시 블록의 크기는 2^m의 워드(2^m+2) 바이트를 가지며 m 개의 비트는 블록 내부에서 워드 구별에 쓰인다. **나머지 두 비트는 주소 중 바이트 구별용으로 쓰인다.
태그 필드의 크기는 32 -(n+m+2)
직접 사상 캐시의 전체 비트의 수는 2^n * (블록 크기 + 태그 크기 + 유효비트 크기)
블록의 크기는 2^m개 워드(2^m+5 비트)이고, 유효 필드를 위해 한 비트가 필요하므로 이 캐시의 전체 비트 수는
아래와 같이 계산된다.
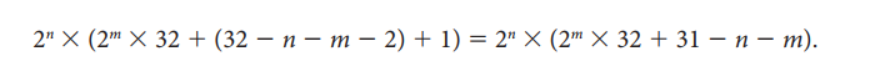
이해를 위해서 예를 드는 것이 가장 빠른 방법이다.
Main memory는 현재 64 Byte이고 (4 Byte * 16)
캐시 메모리는 1 Block당 4 Byte( 1 - word)로 받는다.
4 블럭이니 16 Byte의 크기를 가진 캐시라고 보면 된다.
아래의 그림에선 Main memory의 하위 2비트가 무시된다.
이는 하위 2 비트가 word의 byte를 정의하기 때문이다. 즉, offset이다.
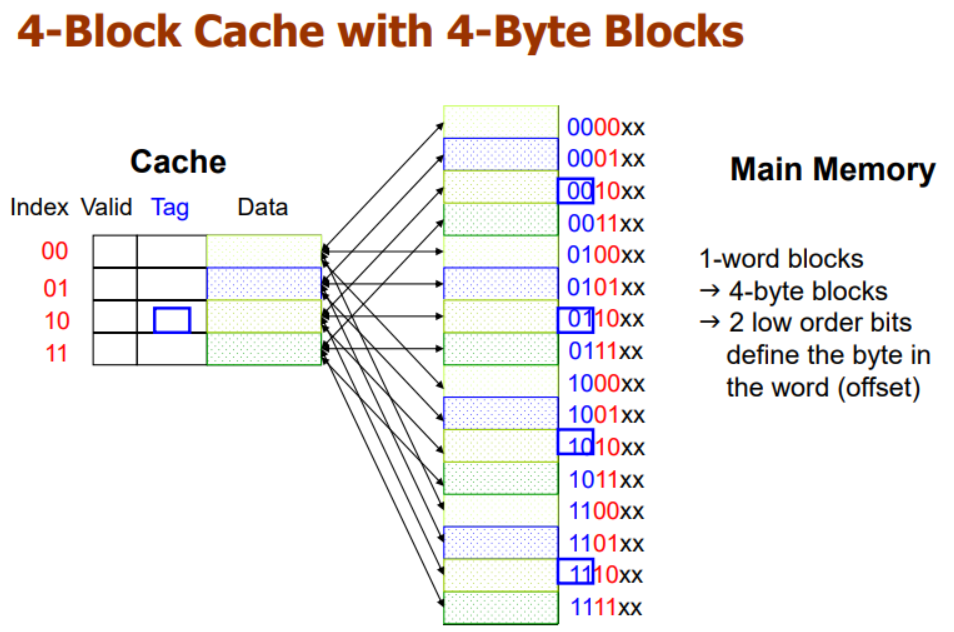
캐시블럭을 보면 Index와 Valid 그리고 Tag라는 것이 있다.
블럭이 4개니까 Index는 2-bit로 해결이 가능하다.
Valid 는 1-bit이고
Tag가 있다.
여기서 Index, 다시 말하면 Cache address는

(블록 주소) modulo (캐시 내에 존재하는 블록의 수) 이다.
위에서 하위 2비트 offset이므로 무시하고 상위 4비트로 계산하는 것이다.
그래서 상위 4로 모듈러 연산을 해서 구할 수 있다.
그림의 빨간색이 곧 index, cache address가 된다.
**2번째 의문점은 해결이 됐다.
그렇다면 Main memory의 4개의 블럭이 캐시의 한 블럭에 매핑된다.
그렇다면 4개의 블럭 중 무엇인지 알아야 한다.
그것이 바로 tag가 하는 역할이다.

다시 말하면 Tag는 특정 계층에서 해당 블록이 요청한 워드와 일치하는지 알려주는 주소 정보
즉, 그림에서 파란부분이 Tag가 된다.
**0번째 의문점은 해결이 됐다.
Valid bit는 해당 캐시가 유효한 address를 가지고 있는지를 보여주는데

처음에는 0 값을 가지고 있고1이라는 것은 캐시에 데이터가 있다는 뜻이다.
프로세서가 맨 처음 작업을 시작하면 당연히 캐시는 비어있을 것이다.
그래서 태그 필드는 의미가 없을건데.
많은 명령어를 수행하더라도 주소가 공교롭게도 중복되기만해서 빈칸이 있을 수도 있다.
그래서 비어있는 캐시블럭에 대해 굳이 Tag와 index를 조사하는 일이 없도록 하게하기 위함이라고 보면 된다.
요약하자면 메모리주소 -> 블럭주소 -> 캐시주소
이런 순으로 바뀐다고 보면 된다.
가장 간단한 방법인 Direct mapping, 직접 사상에 대해 살짝 알아보자.
위에서도 썼지만 한 번 더 복습하자

이러한 방법에서도
cash address를 이렇게 구할 수 있다.
위에 00001이 캐시의 001블럭에 매핑되는 것을 보면 저 식이 맞다는 것을 느낄 수 있다.
8블록 캐시는 캐시 주소로 블록주소의 하위 3비트를 사용한다.
참고로 위에 나와있는 것은 block address지 Memory address는 아니다.
이것을 잘 구분해야한다. ( Memory address != Block address)
메모리 주소의 단위는 byte다.
**메모리의 주소 값을 블럭의 크기로 나누는 것이 block address가 된다.
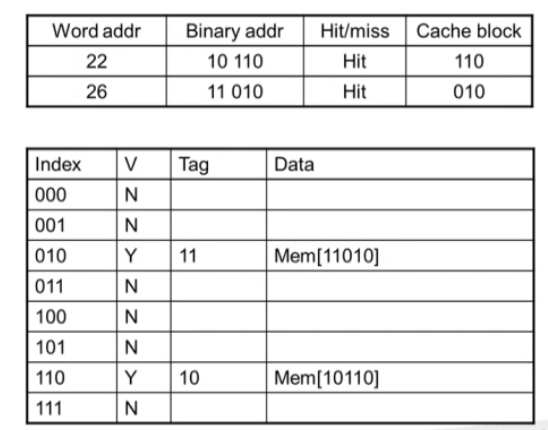
다시 예를 들어보자

이것이 처음 조건이다.

Word address는 여기서는 block address라고 볼 수 있다.
word address 를 이진수로 바꾸면 10110이 되는 것이다.
초기엔 Valid가 N이니 바로 miss로 메모리에서 블럭을 찾아서 넣어야 한다.
2번째는

3번째는 Hit이 나왔다. 보자
4번째는 Hit과 Miss다.
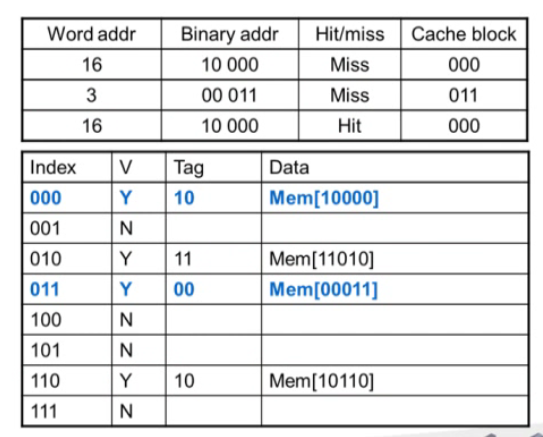
이번엔 miss로 캐시 블럭의 교체를 요구한다.
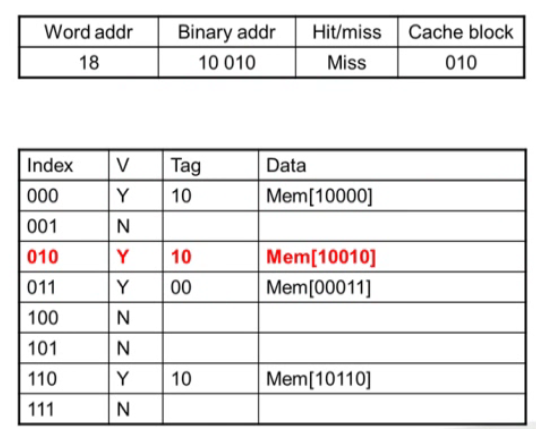
메인 메모리에서 블럭을 가져온다.
이런 식으로 캐시에 블럭을 가져온다는 것을 알아두자.
하지만 저렇게 우리가 따로 블럭을 떼어내어 보는 것 보다는
어떻게 회로에서 구성되는지 알아봐야겠지?
이번엔 캐시가 4KB의 크기를 가진다.
1-Word block(4 byte)이기에 메모리 주소는 32bit이고 byte offset은 여전히 하위 2비트이다.

캐시가 가질 수 있는 블럭의 수는 4KB/4Byte 즉, 1024개의 블럭이다.
1024개의 블럭은 10비트로 표현할 수 있다.
즉, 하위 2비트를 제외하고 2번부터 ~12번까지가 index가 된다고 말할 수 있겠고
그 위가 Tag가 된다고 말할 수 있다.
만약 block size가 1-word보다 커지면 어떨까??

여기선 4-word의 블럭을 말한다.
memory address 1200으로 block address를 구해보자
사실 몫만 취하면 된다.
해당 블럭이 중요한 것이지 블럭이 어느 부분인지는 상관없다.
이제 cache에 들어가는 index는 64개의 블럭이므로 11이 나오고
이진수로 바꿔주면 된다.
001011이 되겠다. 8 + 2 + 1
하나만 더 보고 이해하자

이번엔 다른 종류의 캐시 방법을 보자
Data를 여러개 저장하는 것이다.
하나의 캐시 블럭에 데이터를 4 Word를 저장하는 것이다.
그래서 이번에는 Byte offset이 1 word가 아니라 4 Word라서 하위 4비트를 차지한다.

1블럭에 4 word(32byte)이고 캐시용량이 4KB인데다가.
1 캐시블럭에 4개 블럭을 집어넣는다
즉, 4KB /(32 B * 4) 개의 블럭 개수를 가지게 된다.
256개의 블럭을 가지게 되고 index는 8비트로 표현이 가능하다.
Tag는 자동으로 20비트가 된다.
하지만 Hit 했을 경우에도 4가지 Word중 어떤 Word인지 골라야 하기 때문에
Word를 표현하는 최하위 2비트 빼고 그 다음 4개의 Word를 의미하는 2비트를 가지고
block offset을 만든다. 2비트면 11,10,01,00 으로 4가지 Word 중 맞는 Word를 고를 수 있다.
이 캐시는 가져올 때 4개를 한꺼번에 가져오기 때문에
공간 지역성
또한 캐시블럭에 올려놓고 사용하므로
시간 지역성
2가지 지역성을 모두 활용하는 예가 된다.
뭐야 그러면 항상 Multiple로 사용하고 최대한 많이 해놓으면 되는거 아냐???
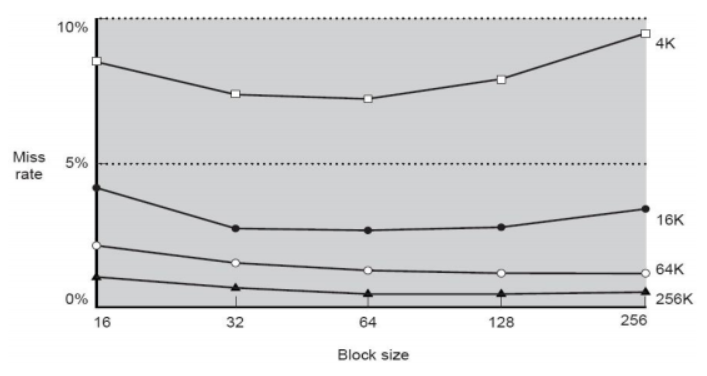
컴퓨터에 관련된 거의 모든 것들은 trade-off의 관계이기 때문에
그렇게 단순하게 생각하기보다 진짜 한 번 생각을 해야한다.

블럭이 커질수록 공간의 지역성을 활용하기 때문에miss rate가 낮아질 확률이 높다.
하지만 캐시의 사이즈가 고정되어 있다면 블럭이 커질수록 해당 블럭에 많은 메모리가 매핑된다.
블럭의 수는 줄어드니 그만큼 교체가 잦아질 수도 있는 것이다.
또한 블럭이 커지면해당 블럭을 읽는 것 자체도 오버헤드가 되어 성능이 떨어질 수도 있다.
miss panalty - 즉, 시간이 더 걸릴 수 있는 것이다.
** 그런 것을 보완하기 위한 방법도 있는데
4개의 블럭을 받는다 치면
내가 4개를 다 읽지 않더라도 내가 2번째 워드를 먼저 쓰면서 불러올 수 있다는 말이다.
그렇다면 이번엔 캐시 미스에 대해서 더 알아보자

당연히 hit하면그냥 그대로 수행한다.
다만 miss가 된다면
하위 레벨 메모리로 가서 가져와야한다.
그리고 2가지 종류의 miss가 있다.
Instruction cache miss와 Data cache miss

그동안 processor는 stall되어 있다
또한 캐시를 쓰는 방법에는 2가지가 있다.
Write-Through와 Write-Back

store 명령을 했지만 캐시에만 적용하고 메모리에 쓰지 않는 경우고 있다.
다시 말하면 이런 경우다.
캐시를 쓰고있는데 hit 되었다면 캐시 블럭을 그냥 갱신해주면 된다.
캐시에서 계산한 값을 메모리에 갱신하지 않으면 ..
-> 데이터와 메모리에 있는 데이터가 달라짐
메모리에 쓰는 시간과 캐시 블럭에서 사용하는 시간이 다르기 때문에 생기는 문제다.

그 해결방법이 Write Through이다.(즉시 쓰기라고도 한다)
Write buffer를 이용해 메모리에 쓸 데이터를 버퍼에 놓고 버퍼는 계속 메모리에 쓰는 작업을 진행하고 우리는 캐시를 업데이트해서 계속 사용할 수 있게 된다.
** Write buffer가 꽉차지 않는 이상 stall이 발생하지 않는다.
다음 방법은 Write Back이다. (나중 쓰기라고도 한다.)

쓰기가 발생했을 때, 캐시에만 update를 하는 것이다.
하지만 어떤 캐시에 있는 데이터가 update 가 되었는지를 기록하는 것이다. (dirty)
해당 dirty 블럭이 캐시 블럭에서 내려갈 때, 그제서야 memory에 write를 하는 것이다.
즉교체할 때 기존에 있는 블럭을 write buffer에 올리고 replace된 블럭을 캐시에 넣는 것이다.
다시 말하면 캐시에서 교체가 일어날 때, 쓰기에 의해 내용이 바뀐 블록이면 메모리 계층 구조의 더 낮은 계층에 써진다.
**여전히 버퍼가 꽉차면 stall이 발생한다.
**나중 쓰기 방식은 특히 메인 메모리가 처리할 수 있는 속도보다 프로세서가 쓰기를 더 빠르게 발생시키는 경우 좋다.
위의 2가지 방법 다Write buffer를 사용함으로써 메모리에 write하는 시간이 긴 것을 보완할 수 있게 되는 것이다.
Write 에서 miss가 났을 경우, 쓰기 연산을 실패했을 경우가 있다.
이 경우가 중요하다.

Write-through같은 경우에 해당 블럭을 캐시에 올리면서 메모리에도 쓰게된다.
캐시에 블록을 할당하는 것인데 이를 쓰기 할당(write allocate)라고 부른다.
일단 전체 블록을 메모리에서 읽어 온 후, 블록 중에서 쓰기 실패를 발생시킨 워드만 덮어 쓴다.
Write-Through 캐시는 데이터를 캐시에 쓰고 태그값을 읽을 수 있다.
만약에 태그가 일치하지 않는다면 실패가 발생한다.
캐시가 Write-Through 방식이므로
캐시에 블록을 바로 덮어써도 메모리가 정확한 값을 갖고 있기 때문에 문제가 되지는 않지만
Wrte-Back 방식에서 캐시에 있는 데이터가 갱신된 값인데 캐시 실패가 발생하면
그 블록을 먼저 메모리에 써야만한다.
저장 명령어가 캐시 적중이 확인되기도 전에 캐시 블록에 덮어쓰면( Write-Through처럼 ) 하위 계층 메모리에 저장하지도 않은 블록을 망가뜨린다.
Wrte-Back 캐시는 블록에 바로 덮어쓸 수 없기 때문에,
두 사이클을 사용하거나 또는 데이터를 보관하기 위해 저장 버퍼(store buffer)를 사용해야 한다.
이 버퍼는 쓰기 과정을 파이프라인해서 저장 명령어가 한 사이클만 걸리게 해준다.
저장 버퍼를 사용하면 정상적인 캐시 접근 싸이클에 프로세서가 캐시를 검색하고 데이터를 저장 버퍼에 넣는다. 검색 결과가 캐시 적중으로 밝혀지면, 사용되지 않는 캐시 접근 사이클이 나올 때까지 기다렸다가 새로운 데이터를 저장 버퍼에서 꺼내 캐시에 쓴다.
반면에 Write-Through 캐시에서는 쓰기가 항상 한 싸이클에 수행된다.
태그값을 읽고, 선택된 블록의 데이터 영역에 쓰기만 하면 된다.
만약에 태그값이 써지는 블록의 주소와 일치하면 맞는 블록이 갱신되었기 때문에 프로세서는 정상 동작을 수행한다.
만약 태그가 일치하지 않으면 프로세서는 그 주소에 해당하는 블록의 나머지 부분을 인출하기 위해 쓰기 실패를 발생시킨다.
** 많은 Wrte-Back 캐시들은 실패 시 이미 갱신된 블록을 교체할 때 생기는 손실을 줄이기 위해 쓰기 버퍼를 사용한다.
Write around는 약간 그런 개념이다.
컴퓨터 킬 때 부팅할 때 필요한 것은 사실 부팅 시에만 필요한 경우가 많다.
그래서 굳이 이러한 것들을 모두 써야할 필요는 없다.
굳이 캐시에 올릴 필요가 없고 바로 메모리에서 가져다만 쓰는 것이다.
상용되는 프로세서의 경우를 보고 마치자.

'컴퓨터(Computer Science) > 컴퓨터구조(Computer Arichitecture)' 카테고리의 다른 글
| Cache Performance, 캐시의 성능 [컴퓨터구조] (0) | 2020.06.01 |
|---|---|
| 메모리 계층구조, Memory Hierarchy 에 대한 보충내용[컴퓨터구조] (0) | 2020.06.01 |
| 2의 보수(2's complement) [컴퓨터구조] (0) | 2020.05.18 |
| 컴퓨터 성능이 생각대로 늘어나지 않는 이유, 암달의 법칙(Amdahl's Law)[컴퓨터구조] (0) | 2020.05.18 |
| 컴퓨터의 성능을 가로막는 전력, Power Wall [컴퓨터구조] (2) | 2020.05.17 |