우리는 앞서 CPU, 프로세서의 성능을 측정했다.
즉, 프로세서에서 캐시가 영향을 미치는 정도가 캐시의 성능이 될 것이라고 간접적으로 알 수 있다.

CPU time에 영향을 미치는 요소가 있다.

실제로 프로그램을
CPU가 실행하는 시간과
Data에 접근하는 시간
2가지로 나눌 수 있다.
캐시에서는 Data에 접근하는 시간이 중요하게 여겨진다.

아래의 조건 하에 우리는 CPU 성능을 다르게 표현할 수 있다.


위의 식을 이용하여 실제로 예를 들어서 구해보자

Miss panaty가 100 cycle이다.
-> Main memory에서 가져오는 데 필요한 사이클
Base CPI (모두 다 cache hit만 할 경우의 CPI를 말한다.)
Load/Store -> 메모리에 접근하는 instruction이 36%
답은 위와 같이 구한다.
Hit 는 캐시의 성능에 있어서 중요하다.
그래서 대표하는 지표를 하나 만들어냈는데
평균 접근 시간이다.

AMAT라고 부른다.
위의 예는 간단하게 표현한 것이고
**사실 고려할 때는 I-cache 뿐만 아니라 D-cache도 포함해야 정확하다.
다시 캐시 성능에 대해서 생각해보면

이전의 Memory Wall을 말했듯이
CPU가 아무리 빨라져도 캐시가 좋지 않으면 해당 프로세서의 성능을 발휘하는데 제약이 생긴다.
때문에 Miss penalty가 중요해지고
Base CPI를 줄여야 한다.
실제로 Memory stall의 대부분을 개선해야한다는 말이다.(캐시)
또한 클럭속도를 높일수록
캐시의 성능이 중요해진다.
즉, 어떠한 프로세서를 측정할 때는 프로세서의 성능도 중요하지만 On-Chip의 캐시 성능도 무지막지하게 중요하다는 것이다.
우리는 기본적으로 캐시를 배울 때
직접 사상, Direct mapping으로 배웠다.
하지만 캐시의 성능을 높이기 위해선 그것만으로는 부족하다.

1. Fully Associative
2. n-way set Associative
두 가지가 있다.
**둘이 Tag Searching 방법이 다르다.

Fully Associative의 경우
해당 블럭이 캐시의 어느 블럭에나 갈 수 있게 한다.
이 말 뜻은
캐시가 한 라인이 있다면 그 모든 라인이 Comparator에 의해서 한 번에 모든 entry를 비교한다.
하지만 너무 비싸서 잘 사용되지는 못한다.
차이는 아래와 같다.


n-way Associative의 경우
direct와 fully의 중간이라고 보면 된다.

하나의 set에 n개의 entries가 들어가는 것을 말한다.
여기서는 특정한 entries를 계산해야 할 필요성이 생긴다.
때문에 block number를 set의 수로 나누는 작업을 하기도 한다.
그래도 역시나 set을 조사할 때는 n개를 한꺼번에 조사한다.
하지만 1번보다는 comparator가 덜 들기에 덜 비싸다.
아래와 같다.

여기선 2개의 entries 조사함을 볼 수 있다.
예제를 보면서 알아보자.
도대체 Associative가 뭔지 알아보자
이 캐시는 8개의 entries를 가지고 있다고 가정했다.

우리가 흔히 말하는 라인, 블럭 수가 여기서는 Set이라고 부른다.
다른 예제를 또 보자

위의 4 Entries를 가지고 있는 캐시를 보자
3가지 방법에 대해 다 알아보자.
1. Direct

0번을 접근하지만 처음엔 Miss
다음엔 8이니까 4로 나눈 나머지가 0이므로 0번 접근하지만 0내용이 들어있으므로 Miss
다시 0 접근하지만 8이 들어있으므로 Miss
2번은 처음이므로 Miss
0번엔 0이 들어있으므로 Miss
다 미스남.
2. 2-way
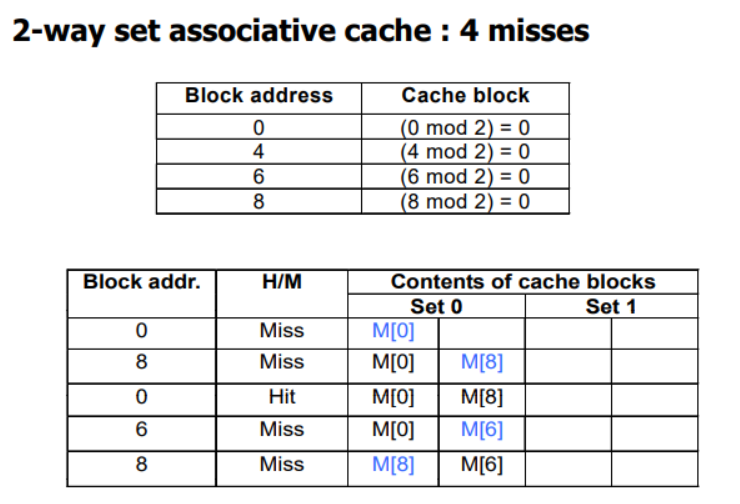
Set이 2개므로 2로 나머지 연산한다.
0 처음이므로 Miss
8 Set 0에 없으므로 Miss
0 Set 0 에 있으므로 Hit
6 Set 0 에 없으므로 Miss 최근에 쓰인 0 대신 6을 뺌
8 Set 0 에 없으므로 Miss 최근에 쓰인 6 대신 0을 뺌
3. Fully(4-way)

Set이 하나란 얘기다.
Set으로 나눌 필요도 없다.
순서대로 들어간다. 있으면 Hit 없으면 Miss 하고 캐시에 올린다.
당연한 얘기지만
Set에 있는 n개의 블럭, n개의 entries가 많을수록 히트율이 올라간다.


음 그렇지만 Associativity 가 증가하면 히트율이 올라가는 것은 맞지만
실제로의 성능은 점점 떨어진다. 위의 그래프를 보면 알듯이
점점 기울기가 완만해지는 것이 보인다.
hit time을 떨어뜨리기 때문이다.

Associativity를 이용한 캐시 구조는 이렇다.

32비트는 이렇게 쓰인다.

아까는 내가 캐시 Miss가 나서 캐시를 갱신, 교체할 때
최근에 쓰이지 않은 캐시를 내리고(LRU) 올리는 방법을 썼는데
가장 적게 refer된 캐시를 내리거나 오래 남아있는 순서대로 내린다던가 여러 방법이 있지만
대표적인 방법 몇 개를 가져왔다.

우리는 캐시의 성능을 최대한 이끌어내기 위해서
L1,L2,L3 요즘은 L4도 나온다는 것 같은데
이렇게 Multi Level Cache를 사용한다.

이러한 것들도 캐시의 성능을, CPU의 성능을 결정하는 좋은 요소 중 하나다.
예를 들어 설명하자면
L1캐시만 있을 때는..?

L2가 있다면?

2.6배 성능이 상승했다.
다시 정리하자

일반적으로 L1 캐시, Primary Cache는 주로 hit time을 줄이는 데에 사용된다.
L2는 miss rate를 줄이는데 사용된다.
때문에 캐시 레벨이 하위로 갈 수록 용량이 커지는 이유다.
최종적으로 캐시 성능을 높이기 위한 방법을 정리하자면

hit time을 줄여야 한다.
hit가 나더라도 언제 hit가 나는지를 말하는 것이다.
예를 들면 100평 짜리에 내가 원하는 과자가 있긴 한데... 어디있는지 모른다면
찾아야 한다.
그것이 hit time이다. 있더라도 찾아야 먹지

100평 짜리 창고에 내가 필요한 것을 넣어야 한다.
내가 많이 필요하면 많이 넣어야겠지?
만약 필요한 것도 다 못넣으면 다른 창고가서 찾아와야한다.

하지만 다른 창고가 100미터 멀리 떨어져있으면
내 창고로 옮기는데 시간이 많이 걸리겠지??
그것이다.
모든 관계는 거의 trade-off 관계로
캐시의 성능 높이기 위해서는 고려해야 할 점이 아주 많다.


요즘 CPU같은 경우
Out-of-order를 가지고 있고
실제 load/store 나 dependent instruction의 경우에도 reservation station에 두면서 다른 것은 작업을 한다.
결국 캐시의 성능은 프로그램 자체의 data flow에 따라 결정되는데
이것이 점점 분석하기가 힘들어지다보니
시뮬레이션으로 찾아내서 최적화하는 작업이 이뤄지고 있다는 말이다.
'컴퓨터(Computer Science) > 컴퓨터구조(Computer Arichitecture)' 카테고리의 다른 글
| 컴퓨터 구조 관련 내용 리뉴얼 (0) | 2021.06.17 |
|---|---|
| 컴퓨터 구조에서 본 가상메모리, Virtual memory - 기본 개념 [컴퓨터구조] (0) | 2020.06.01 |
| 메모리 계층구조, Memory Hierarchy 에 대한 보충내용[컴퓨터구조] (0) | 2020.06.01 |
| 캐시, Cache - 기본 원리 [컴퓨터구조] (1) | 2020.05.25 |
| 2의 보수(2's complement) [컴퓨터구조] (0) | 2020.05.18 |