구글링 + 학교 공부로 작성하였습니다.
피드백 맘껏 양껏 주세요
업데이트(22.06.01)
자료구조 별 접근, 삽입, 삭제, 탐색, 시간
**체크한 것들은 최악의 경우가 존재함( 사용자의 능력에 달림)
ex) 해시테이블, BST

배열, 연결리스트
배열, 연결리스트, List
[컴퓨터(Computer Science)/자료구조(Data Structure)] - 배열, 함수의 매개변수,주소,값,자료구조(2)
[CS Interview] - C++ 에서의 자료구조 Array vs Linked List; 배열과 연결리스트
[프로그래밍언어(Programming Language)/C || C++] - 연결리스트, Linked List [CPP]
[프로그래밍언어(Programming Language)/C || C++] - STL 리스트, list 사용법 [C++]
[CS Interview] - C++ 에서의 자료구조 list를 쓰는 이유
스택
큐
큐
[프로그래밍언어(Programming Language)/C || C++] - Queue, 큐 , 자료구조 [CPP]
덱
[프로그래밍언어(Programming Language)/C || C++] - Deque, 덱 , 자료구조 [CPP]
우선순위 큐
[프로그래밍언어(Programming Language)/C || C++] - STL 우선순위 큐, Priority Queue 사용법 [C++]
힙
[컴퓨터(Computer Science)/자료구조(Data Structure)] - [C언어] 자료구조 - 우선순위 큐 heap 힙 -2
[컴퓨터(Computer Science)/자료구조(Data Structure)] - [C언어] 자료구조 - 우선순위 큐 heap 힙 기본연산 -3
해시
해시
[CS Interview] - 해시 테이블, Hash Table 의 장단점 및 한계
[문제풀이(Problem Solving)/C++ 문제풀이에 유용한 것들] - Hash, 해시 테이블 , 자료구조 [CPP]
[컴퓨터(Computer Science)/자료구조(Data Structure)] - [C언어] 자료구조 - Hash 해시 ,해싱-1
[컴퓨터(Computer Science)/자료구조(Data Structure)] - [C언어] 자료구조 - Hash -오버플로우 처리 방법 및 기본 연산-2
[컴퓨터(Computer Science)/자료구조(Data Structure)] - [C언어] 자료구조 - Hash 체이닝(chaining)-3
맵
[프로그래밍언어(Programming Language)/C || C++] - STL 맵, map 사용법 [C++]
트리
BST
[컴퓨터(Computer Science)/자료구조(Data Structure)] - Tree 이진탐색트리 Binary Search Tree(BST) [자료구조]
트리
[컴퓨터(Computer Science)/자료구조(Data Structure)] - [C언어] 자료구조 - Tree 트리 -1
[컴퓨터(Computer Science)/자료구조(Data Structure)] - [C언어] 자료구조 - Tree 트리 구현 -2
[컴퓨터(Computer Science)/자료구조(Data Structure)] - [C언어] 자료구조 - Tree 트리 순회,기본연산 -3
MST
[문제풀이(Problem Solving)/C++ 문제풀이에 유용한 것들] - MST, 최소 신장 트리 [CPP]
그래프
그래프
[컴퓨터(Computer Science)/자료구조(Data Structure)] - [C언어] 자료구조 - 그래프 -1
[문제풀이(Problem Solving)/C++ 문제풀이에 유용한 것들] - Graph, 그래프 , 자료구조 [CPP]
Kruskal 알고리즘
[컴퓨터(Computer Science)/자료구조(Data Structure)] - [C언어] 자료구조 - 가중치 그래프 Weighted Graph + Kruscal - 1
Prim 알고리즘
[컴퓨터(Computer Science)/자료구조(Data Structure)] - [C언어] 자료구조 - 가중치 그래프 Weighted Graph + Prim - 2
Dijkstra 알고리즘 (Greedy)
[분류 전체보기] - [C언어] 자료구조 - 가중치 그래프 Weighted Graph + Dijkstra -3
Floyd 알고리즘
[컴퓨터(Computer Science)/자료구조(Data Structure)] - [C언어] 자료구조 - 가중치 그래프 Weighted Graph + Floyd -4
정렬
삽입, Insertion
[CS Interview] - 삽입 정렬, Insertion Sorting 에 대하여
퀵, Quick
[컴퓨터(Computer Science)/자료구조(Data Structure)] - [C언어] 자료구조 -정렬(sorting) - 1, 선택정렬
병합, Merge
[CS Interview] - 병합 정렬, Merge Sorting 에 대해서
선택, Selection
[컴퓨터(Computer Science)/자료구조(Data Structure)] - [C언어] 자료구조 -정렬(sorting) - 1, 선택정렬
버블, Bubble
쉘, Shell
힙, Heap
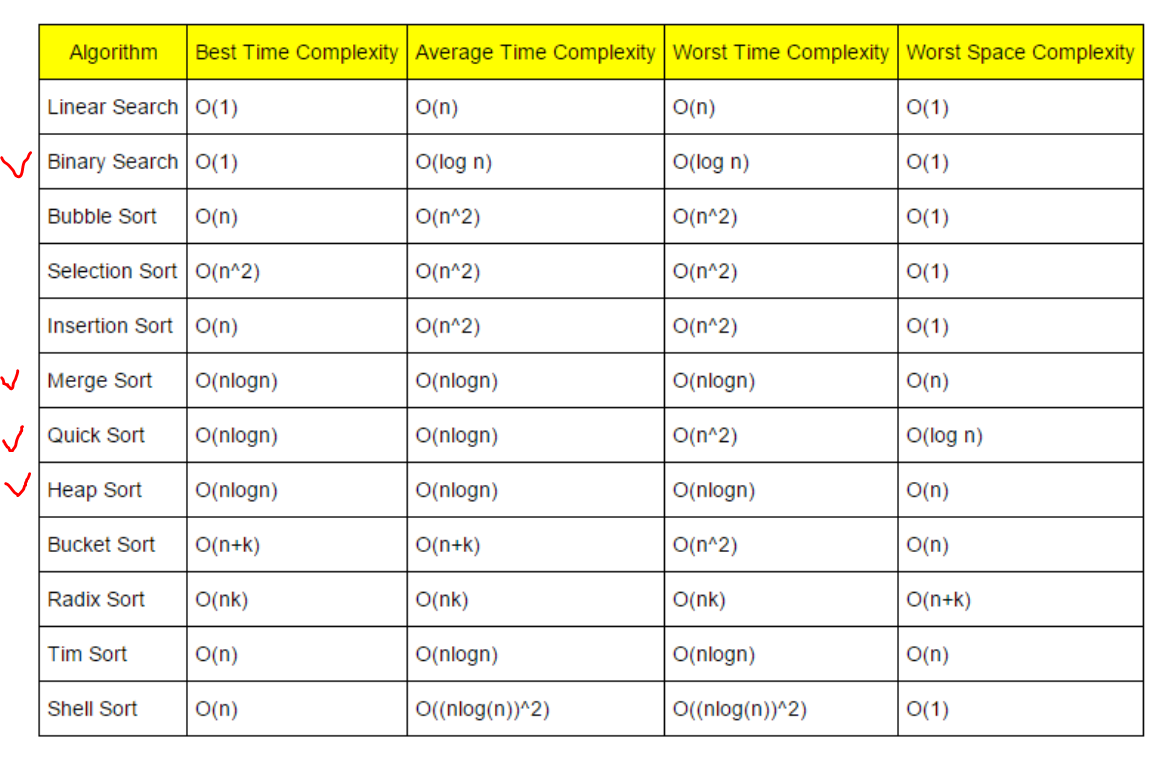
탐색
개념 질문
Q. 스택에 대해서 설명해주세요.
A.
스택은 먼저 들어간 자료가 마지막으로 나오게 되는 First In Last Out 구조를 가지고 있다.
일반적으로 접시를 쌓아놨을 때 항상 위에 것부터 닦는 것과 같다.
삽입과 삭제가 일어나는 장소가 같다는 특징이 있다.
Q. 큐에 대해서 설명해주세요
A. 큐는 먼저 들어간 자료가 먼저 나오는 First In First Out의 구조를 가지고 있다.
우리가 줄을 선 대로 들어가는 것처럼 차례대로 무엇인가를 하는 것을 의미한다.
=> Event Queue라는 디자인 패턴이 큐의 특징을 이용한 대표적인 예이다.
Q. Tree가 무엇인가?
정점과 간선을 이용해 사이클을 이루지 않도록 구성한 Graph의 한 종류다.
계층이 있는 데이터를 표현하기에 적합하다.
Q. Heap이 무엇인가?
일반적으로 최댓값 또는 최솟값을 찾아내는 연산을 쉽게 하기 위해 고안된 구조이다.
각 노드의 키값이 자식의 키값보다 작지 않거나(최대힙) 그 자식의 키값보다 크지 않은(최소힙) 완전이진트리이다.
Q. 우선순위 큐란?
우선순위큐는 가장 우선순위가 높은 데이터를 먼저 꺼내기 위해 고안된 자료구조다.
우선순위 큐를 구현하기 위해서 일반적으로 힙을 사용한다.
== 반대로 우선순위 큐가 Heap이라고 생각해도 된다.
힙은 완전이진트리를 통해서 구현되었기 때문에 우선순위 큐의 시간복잡도는 O(logn)이다.
Q. Hash Table에 대해서 설명해주세요.
해시 테이블은 (Key, Value)로 데이터를 저장하는 자료구조다.
빠른 데이터 검색이 필요할 때 유용하다.
해시 테이블은 Key값에 해시함수를 적용해 고유한 index를 생성하여 그 index에 저장된 값을 꺼내오는 구조다.
해시 테이블은 고유한 index로 값을 조회하기 때문에 평균적으로 O(1)의 시간복잡도를 가진다.
하지만 해시의 index값이 충돌이 발생한 경우, 충돌 시 알고리즘에 따라 최악의 경우 O(N)의 시간복잡도를 가질 수 있다.
Q. 최소 스패닝 트리(Minimum Spanning Tree)에 대해서 설명해주세요.
그래프 G의 스패닝 트리 중 edge weight 값이 최소인 스패닝 트리를 말한다.
스패닝 트리란 그래프 G의 모든 vertex가 cycle 없이 연결된 형태를 말한다.
-> 모든 노드가 연결되어있지만 최소 값을 가지게끔 연결되어 있음
n개의 vertex를 가지는 그래프에서 반드시 (n-1)개의 edge만을 사용해야 하며 사이클이 포함되어서는 안 된다.
** Kruskal과 Prim을 통해서 MST를 구현할 수 있다.
Kruskal의 경우 그래프의 간선들을 오름차순으로 정렬하여 가장 낮은 가중치의 간선부터 차례로 MST에 집합체 추가하는 그리디 알고리즘 방식을 사용한다.
Prim의 경우는 시작 정점부터 단계적으로 트리를 확장하는 방법이다.
Q. BST에 대해서 설명하세요.
A. 이진탐색트리(Binary Search Tree)는 이진 탐색과 연결 리스트를 결합한 자료구조다.
이진 탐색의 효율적인 탐색 능력을 유지하면서, 빈번한 자료 입력과 삭제가 가능하다는 장점이 있다.
이진 탐색 트리는 왼쪽 트리의 모든 값이 반드시 부모 노드보다 작아야 하고, 반대로 오른쪽 트리의 모든 값이 부모 노드보다 커야 하는 특징을 가지고 있어야 한다.
이진 탐색 트리의 탐색, 삽입, 삭제의 시간복잡도는 O(h) == O(log N)이다.
트리의 높이에 영향을 받는데, 트리가 균형이 맞지 않으면 워스트 케이스가 나올 수 있다. 그래서 이 균형을 맞춘 구조가 AVL Tree이다.
=> BST의 특징을 같는 AVL 트리는 Red-Black Tree이다.
Q. 동적 프로그래밍(Dynamic Programming)이란?
동적 프로그래밍(Dynamic Programming) 이란 주어진 문제를 풀기 위해서, 문제를 여러 개의 하위 문제(subproblem)로 나누어 푼 다음, 그것을 결합하여 해결하는 방식이다.
-> 하위 문제로 나눌 수 없으면 DP 방법으로 풀 수 없다.
동적 프로그래밍에서는 어떤 부분 문제가 다른 문제들을 해결하는데 사용될 수 있어서
같은 답을 여러 번 연산해서 사용하는 대신 한 번만 연산하고 그 결과를 재활용하는 메모이제이션(Memoization) 기법으로 속도를 향상 시킬 수 있다.
Q. 동적 프로그래밍(Dynamic Programming)의 두 가지 조건
동적 프로그래밍(Dynamic Programming)으로 문제를 해결하기 위해서는 주어진 문제가 다음의 조건을 만족해야 한다.
1. Overlapping Subproblem(중복되는 부분문제): 주어진 문제는 같은 부분 문제가 여러번 재사용된다.
2. Optimal Substructure(최적 부분구조): 새로운 부분 문제의 정답을 다른 부분 문제의 정답으로부터 구할 수 있다.
Q. AVL 트리란?
A.
AVL 트리란 한 쪽으로 값이 치우치는 이진 균형 트리(Balanced Search Tree, BST)의 한계점을 보완하기 위해 만들어진 균형 잡힌 이진 트리다.
AVL은 항상 좌/우로 데이터를 균형잡힌 상태로 유지하기 위해 추가적인 연산을 진행합니다.
(Root Node가 바뀜)
-> 덕분에 항상 검색 속도를 O(log N)으로 유지할 수 있다.
응용질문
Q. Quick Sort를 코드로 구현해주세요.
// C++에서의 퀵소트 => Divide & Conquer
#include <iostream>
using namespace std;
//재귀로 구현함 => pivot의 위치는 임의로 start로 정함
//정복하는 부분 (Conquer)
int partition(int arr[], int start, int end)
{
// pivot을 정함
int pivot = arr[start];
int count = 0;
//pivot을 제외한 나머지 원소들을 탐색하면서 pivot보다 작은 애들 count
for (int i = start + 1; i <= end; i++) {
if (arr[i] <= pivot)
count++;
}
//pivot을 count만큼 이동시킴
int pivotIndex = start + count;
swap(arr[pivotIndex], arr[start]);
// pivot을 기준으로 다시 탐색함
int i = start, j = end;
while (i < pivotIndex && j > pivotIndex) {
//pivot보다 왼쪽에 있으면 pivot보다 작거나 같아야함.
while (arr[i] <= pivot) {
i++;
}
// pivot보다 오른쪽에 있으면 pivot보다 커야함.
while (arr[j] > pivot) {
j--;
}
//만약 그렇지 않다면 i원소와 j 원소의 자리를 바꿔준다.
if (i < pivotIndex && j > pivotIndex) {
swap(arr[i++], arr[j--]);
}
}
//pivot의 위치 반환
return pivotIndex;
}
//분할하는 부분(Divide)
void quickSort(int arr[], int start, int end)
{
//start가 end가 되면 정렬이 끝
if (start >= end)
return;
// divide를 함
int p = partition(arr, start, end);
// divide한 부분에 대해서 Quicksort 시도
quickSort(arr, start, p - 1);
// 동일
quickSort(arr, p + 1, end);
}
int main()
{
int arr[] = { 9, 3, 4, 2, 1, 8 };
int n = 6;
quickSort(arr, 0, n - 1);
for (int i = 0; i < n; i++) {
cout << arr[i] << " ";
}
return 0;
}
Q. Merge Sort를 코드로 구현해주세요
// C++ 에서의 MergeSort
#include <iostream>
using namespace std;
//Divide & Conquer
void merge(int array[], int const left, int const mid, int const right)
{
auto const subArrayOne = mid - left + 1;
auto const subArrayTwo = right - mid;
//Divide int 2 subarrays
auto *leftArray = new int[subArrayOne],
*rightArray = new int[subArrayTwo];
// 이렇게 안해도 되는데 이렇게 했다.
for (auto i = 0; i < subArrayOne; i++)
leftArray[i] = array[left + i];
for (auto j = 0; j < subArrayTwo; j++)
rightArray[j] = array[mid + 1 + j];
auto indexOfSubArrayOne = 0, // Initial index of first sub-array
indexOfSubArrayTwo = 0; // Initial index of second sub-array
int indexOfMergedArray = left; // Initial index of merged array
//정렬
while (indexOfSubArrayOne < subArrayOne && indexOfSubArrayTwo < subArrayTwo) {
if (leftArray[indexOfSubArrayOne] <= rightArray[indexOfSubArrayTwo]) {
array[indexOfMergedArray] = leftArray[indexOfSubArrayOne];
indexOfSubArrayOne++;
}
else {
array[indexOfMergedArray] = rightArray[indexOfSubArrayTwo];
indexOfSubArrayTwo++;
}
indexOfMergedArray++;
}
// Copy the remaining elements of
// left[], if there are any
while (indexOfSubArrayOne < subArrayOne) {
array[indexOfMergedArray] = leftArray[indexOfSubArrayOne];
indexOfSubArrayOne++;
indexOfMergedArray++;
}
// Copy the remaining elements of
// right[], if there are any
while (indexOfSubArrayTwo < subArrayTwo) {
array[indexOfMergedArray] = rightArray[indexOfSubArrayTwo];
indexOfSubArrayTwo++;
indexOfMergedArray++;
}
}
// begin is for left index and end is
// right index of the sub-array
// of arr to be sorted */
void mergeSort(int array[], int const begin, int const end)
{
if (begin >= end)
return; // Returns recursively
auto mid = begin + (end - begin) / 2;
mergeSort(array, begin, mid);
mergeSort(array, mid + 1, end);
merge(array, begin, mid, end);
}
// UTILITY FUNCTIONS
// Function to print an array
void printArray(int A[], int size)
{
for (auto i = 0; i < size; i++)
cout << A[i] << " ";
}
// Driver code
int main()
{
int arr[] = { 12, 11, 13, 5, 6, 7 };
auto arr_size = sizeof(arr) / sizeof(arr[0]);
cout << "Given array is \n";
printArray(arr, arr_size);
mergeSort(arr, 0, arr_size - 1);
cout << "\nSorted array is \n";
printArray(arr, arr_size);
return 0;
}
Q. Merge Sort와 Quick Sort가 비슷해 보이는데 차이가 무엇인가요?
Q. LinkedList와 ArrayList 차이는?
A.
ArrayList는 데이터들이 순서대로 늘어선 배열의 형식을 취하고 있지만
LinkedList는 자료의 주소값으로 서로 연결된 형식을 가지고 있다.
- ArrayList
- 원하는 데이터에 무작위로 접근할 수 있다. (Random Access 가능)
- 리스트의 크기가 제한되어 있으며, 리스트의 크기를 재조정하는 것은 많은 연산이 필요하다. -> (새로운 메모리 블럭을 찾아야 하기 때문)
- 데이터의 추가/삭제를 위해서는 임시 배열을 생성하여 복제하고 있어 시간이 오래 걸린다.
- LinkedList
- 리스트의 크기에 영향 없이 데이터를 추가할 수 있다. -> (연속적 메모리 할당이 아니기 때문)
- 데이터를 추가하기 위해 새로운 노드를 생성하여 연결하므로 추가/삭제 연산이 빠르다.
- 무작위 접근이 불가능하며, 순차 접근만이 가능하다. ->(일반적으로 이전 노드에 포인터가 있다.)
Q. Array와 LinkedList의 차이가 무엇인가요?
A.
Array는 Random Access를 지원한다.
요소들을 인덱스를 통해 직접 접근할 수 있다.
따라서 특정 요소에 접근하는 시간복잡도는 O(1)이다.
반면 Linkedlist는 Sequential Access를 지원한다.
어떤 요소를 접근할 때 순차적으로 검색하며 찾아야 한다.
따라서 특정 요소에 접근할 때 시간복잡도는 O(N)이다.
저장방식도 배열에서 요소들은 인접한 메모리 위치에 연이어 저장된다. (연속적 메모리 할당)
반면 Linkedlist에서는 새로운 요소에 할당된 메모리 위치 주소가 linkedlist의 이전 요소에 저장된다.
배열에서 삽입과 삭제는 O(N)이 소요되지만 -> 잦은 삽입, 삭제에 좋지 않음
Linkedlist에서 삽입과 삭제는 O(1)이 소요된다. -> 잦은 삽입, 삭제에도 괜찮음
배열에서 메모리는 선언 시 컴파일 타임에 할당이 된다.(정적 메모리 할당)
반면 Linkedlist에서는 새로운 요소가 추가될 때 런타임에 메모리를 할당한다.(동적 메모리 할당)
-> 꼭 그런 것은 아니다.
배열은 Stack 섹션에 메모리 할당이 이루어진다.
반면 Linkedlist는 Heap 섹션에 메모리 할당이 이루어진다.
Q. Array를 적용시키면 좋을 데이터가 있다면 Array를 적용하면 좋은 이유, 그리고 Array를 사용하지 않으면 어떻게 되는지 함께 서술해주세요.
A.
일반적으로 주식 차트가 있다.
주식 차트에 대한 데이터는 요소가 중간에 새롭게 추가되거나 삭제되는 정보가 아니며, 날짜별로 주식 가격이 차례대로 저장되어야 하는 데이터다.
또한 순서가 굉장히 중요한 데이터 이므로 Array 같이 순서를 보존해주는 자료구조를 사용하는 것이 좋다.
-> 삽입과 삭제에 새로운 메모리 블럭을 할당해야함 ( O(N)의 시간복잡도)
-> 즉, 삽입과 삭제가 거의 일어나지 않는 데이터가 좋음
-> 연속적으로 저장되어 있어서 Index가 곧 순서가 되므로 순서가 있는 데이터에 알맞음
이와 같은 데이터에 Array를 사용하지 않는 경우
삽입 삭제가 자유롭더라도 검색 시간이 증가하거나, Index 순서가 해당 데이터 순서를 보장하지 않음
Q. 배열은 size가 변경될 수 있는가?
A. 실제로 배열은 동적으로 할당되지 않는다면 size를 변경할 수 없으며
동적으로 할당할 경우 메모리를 해제한 후 더 큰 size의 배열을 선언할 수 있다.
C++에서는 동적으로 Size가 변하는 배열 기반의 Container를 제공하는데 Vector라고 부른다.
Vector는 처음부터 크게 메모리를 확보한다.
Vector는 size와 확보한 메모리가 다른데
capacity라고 하고 capacity가 초과되면 그제서야 다른 메모리 블럭에
더 큰 연속된 메모리영역을 확보해서 이용한다.
Q. 삽입 삭제를 많이해야할 때는 어떤 자료구조를 사용하는 것이 좋을까?
삽입, 삭제의 시간 복잡도가 낮은 연결리스트를 이용해서 구현하는 것이 낫겠다.
만약 검색을 빠르게하고 싶다면 Hash Table도 쓸 수 있다.
Q. 동적(가변) 자료구조는 무엇이 있는가?
Q. STL Container의 set은 어떻게 동작하는가?
내부적으로 비교함수 Compare가 있어서 Element 들이 기본적으로 오름차순으로 정렬된다.
이렇게 할 수 있는 이유는 BST로 작동하기 때문이다.
그렇기에 Unique한 값만 받으면서 정렬된 것을 유지할 수 있다.
Q. STL Container의 unordered_set은 어떻게 동작하는가?
set과 다르게 Hash table을 이용하며 같은 Key를 가지지 못하게 함으로써 중복을 제거할 수 있다.
그리고 검색속도가 set에 비해 빠르다.
Q. Hash값은 중복될 수 있는데 Hash의 충돌을 피할 수 있는 방법은 무엇인가요?
1. Hash Function을 더 좋은 것으로 바꾼다. => 중복된 키 값이 나오지 않도록
2.버킷에 들어가는 원소를 연결리스트로 구현하여 중복되더라도 해당 인덱스에 삽입하는 Chaining 기법을 사용한다.
- 연결 리스트를 사용하는 방식(Linked List): 각각의 버킷(bucket)들을 연결리스트(Linked List)로 만들어 Collision 이 발생하면 해당 bucket 의 list 에 추가하는 방식이다.
- Tree 를 사용하는 방식 (Red-Black Tree): . 데이터의 개수가 적다면 연결 리스트를 사용하는 것이 맞다. 트리는 기본적으로 메모리 사용량이 많기 때문이다. 데이터 개수가 적을 때 Worst Case 를 살펴보면 트리와 연결 리스트의 성능 상 차이가 거의 없다.
3. Collision 일 때 index를 임의로 바꾸는 알고리즘을 설계한다. => Open Address
- Linear Probing: 순차적으로 탐색하며 비어있는 버킷을 찾을 때까지 계속 진행된다.
- Quadratic probing: 2 차 함수를 이용해 탐색할 위치를 찾는다.
- Double hashing probing: 하나의 해쉬 함수에서 충돌이 발생하면 2 차 해쉬 함수를 이용해 새로운 주소를 할당한다. 위 두 가지 방법에 비해 많은 연산량을 요구하게 된다.
4. Bucket 크기를 Resize한다.
해시 버킷의 개수가 적다면 메모리 사용을 아낄 수 있지만 해시 충돌로 인해 성능 상 손실이 발생한다. 그래서 HashMap 은 key-value 쌍 데이터 개수가 일정 개수 이상이 되면 해시 버킷의 개수를 두 배로 늘린다. 이렇게 늘리면 해시 충돌로 인한 성능 손실 문제를 어느 정도 해결할 수 있다. 또 애매모호한 '일정 개수 이상'이라는 표현이 등장했다. 해시 버킷 크기를 두 배로 확장하는 임계점은 현재 데이터 개수가 해시 버킷의 개수의 75%가 될 때이다. 0.75라는 숫자는 load factor 라고 불린다.
Q. Queue를 이용해 선입선출하는 메시지발송을 만들고 있는데, 만약에 긴급발송건이나 예약발송건이 있으면 먼저 보내줘야 합니다. 어떤 자료구조를 이용하는 것이 좋을까요?
A. 우선순위 큐를 통해서 가장 급한 메세지를 맨 위로 보낼 수 있다.
우선 Heap의 형태를 가지는데 Heap에 들어가는 데이터를 <우선순위, 메세지>라고 생각한다면
Comparator를 이용하여 우선순위 별로 MaxHeap을 구성할 수 있을 것이다.
Q. B-Tree와 BST는 내부적으로 어떤 차이가 있나요? 데이터가 어떻게 저장되나요?
A. 둘 다 B가 들어가지만 앞의 B는 사람이름의 B이고 뒤의 B는 Binary의 B다.
B트리는 이진트리에서 발전되어 자식노드가 2개 이상이 될 수 있고 모든 리프노드들이 같은 레벨을 가질 수 있도록 자동으로 Balance를 맞추는 트리다.
정렬된 순서를 보장하고, Multi-levl Index를 통한 빠른 검색을 할 수 있기 때문에 DB에서 사용한다.
Q. 이진검색트리에서 검색속도가 가장 느린케이스는 데이터가 어떻게 저장되어 있는 경우인가?
일반적으로 BST에서는 Root 노드가 처음에 정해지면 바뀌지 않는다.
때문에 Root 노드가 중앙값을 가지지 않는다면 비효율적인 트리가 생성되고 최악의 경우에
최솟값이나 최댓값이 Root Node가 될 경우 트리의 높이,h 가 n과 같아지는 상황이 생긴다.
그렇게 되면 검색은 O(N)의 시간복잡도를 가지게 된다.
Q. 스택 2개로 큐를 만들어 보시오.
Stk1 , Stk2 가 있다고 하자.
Data를 순서대로 받아서 Stk1에 넣는다.
pop()이 발생할 경우
Stk1 에 있는 현재 데이터를 pop()하면서 Stk2에 넣는다.
그 후 Stk2에서 pop()을 하면 가장 먼저 집어넣었던 원소가 나오게 된다.
Pop()이 끝났으면 다시 Stk1에 Stk2를 모조리 넣고 진행한다.
Q. 큐 2개로 스택을 만들어 보시오.
Q1, Q2가 있다고하자.
Data를 순서대로 Q1에 넣는다.
만약 Pop()이 발생할 경우
Q1에 있는 데이터가 1개만 남을 때까지 Q2에 데이터를 옮긴다.
하나만 남는다면 Q1에서 pop()을 진행하고
다시 Q2에 있는 것들은 Q1에 데이터를 옮기고 다시 진행한다.
Q. Sorting Algorithm에서 stable 하다는 것은 무엇을 의미하는가?
Stable이란 정렬되지 않은 상태에서 같은 키값을 가진 원소의 순서가 정렬 후에도 유지되느냐를 물어보는 것이다.
정렬 후에도 유지된다면 Stable하다고 말할 수 있다.
예를 들어 카드를 보자

오름차순으로 정리한다면
2,4,4,7이 나와야 한다.

2,4,4,7이 나왔다.
-> 하지만 4의 위치가 여전히 하트4, 스페이드4로 순서가 바뀌지 않았다 == Stable

바뀌었다. == Unstable
Q.

A.

이라고 하자.
DFS로 찾아보자. 빨간색이 정방향 간선 파란색이 역방향 간선
Flow & Capacity (Initial)
| s->1 | s->2 | s->3 | 1->4 | 2->1 | 2->3 | 2->6 | 3->6 | 4->t | 4->5 | 5->t | 6->t |
| 0/13 | 0/10 | 0/10 | 0/24 | 0/5 | 0/15 | 0/7 | 0/15 | 0/9 | 0/1 | 0/13 | 0/16 |
try 1: {s,1,4,t}
residual(s,1) = 13, residual(1,4) = 24, residual(4,t) = 9 -> min = 9
| s->1 | s->2 | s->3 | 1->4 | 2->1 | 2->3 | 2->6 | 3->6 | 4->t | 4->5 | 5->t | 6->t |
| 9/13 | 0/10 | 0/10 | 9/24 | 0/5 | 0/15 | 0/7 | 0/15 | 9/9 | 0/1 | 0/13 | 0/16 |
try 2 : {s,1,4,5,t}
residual(s,1) = 4, residual(1,4) = 15, residual (4,5) = 1, residual(5,t) = 13 -> min = 1
| s->1 | s->2 | s->3 | 1->4 | 2->1 | 2->3 | 2->6 | 3->6 | 4->t | 4->5 | 5->t | 6->t |
| 10/13 | 0/10 | 0/10 | 10/24 | 0/5 | 0/15 | 0/7 | 0/15 | 9/9 | 1/1 | 1/13 | 0/16 |
try 3: {s,2,6,t}
residual(s,2) = 10, residual(2,6) = 7, residual(6,t) = 16 -> min = 7
| s->1 | s->2 | s->3 | 1->4 | 2->1 | 2->3 | 2->6 | 3->6 | 4->t | 4->5 | 5->t | 6->t |
| 10/13 | 7/10 | 0/10 | 10/24 | 0/5 | 0/15 | 7/7 | 0/15 | 9/9 | 1/1 | 1/13 | 7/16 |
try 4: {s,2,3,6,t}
residual(s,2) = 3, residual(2,3) = 15, residual(3,6) = 15, residual(6,t) = 9 -> min = 3
| s->1 | s->2 | s->3 | 1->4 | 2->1 | 2->3 | 2->6 | 3->6 | 4->t | 4->5 | 5->t | 6->t |
| 10/13 | 10/10 | 0/10 | 10/24 | 0/5 | 3/15 | 7/7 | 3/15 | 9/9 | 1/1 | 1/13 | 10/16 |
try 5:{s,3,6,t}
residual(s,3) = 10, residual(3,6) = 12, residual(6,t) = 6 -> min = 6
| s->1 | s->2 | s->3 | 1->4 | 2->1 | 2->3 | 2->6 | 3->6 | 4->t | 4->5 | 5->t | 6->t |
| 10/13 | 10/10 | 6/10 | 10/24 | 0/5 | 3/15 | 7/7 | 9/15 | 9/9 | 1/1 | 1/13 | 16/16 |
max cut은 26
min-cut은

Q.

A.
| 시작노드/위치 | 1 | 2 | 3 | 4 | 5 | 6 |
| 0/0 | 30 | 25 | ? | ? | ? | ? |
| 0/2 | 30 | 25 | ? | 52 | 65 | ? |
| 0/1 | 30 | 25 | 50 | 43 | 65 | ? |
| 0/4 | 30 | 25 | 50 | 43 | 60 | ? |
| 0/3 | 30 | 25 | 50 | 43 | 60 | 110 |
| 0/5 | 30 | 25 | 50 | 43 | 60 | 110 |
| 0/6 | 30 | 25 | 50 | 43 | 60 | 110 |
'CS Interview' 카테고리의 다른 글
| 네트워크 - CS 면접 총정리 (0) | 2021.11.23 |
|---|---|
| 프로그래밍 지식 - CS면접 총정리 (0) | 2021.11.23 |
| 데이터 베이스 - CS 면접 총정리 (0) | 2021.11.22 |
| 운영체제 - CS 면접 총정리 (0) | 2021.11.22 |
| 교착상태, Deadlock (0) | 2021.11.01 |