21.09.28 RNN 수식들 내용 업데이트
** RNN, 재귀 신경망(Recursive Neural Network)이 아니라 여기선 순환이다!!
우선 자연어처리에서 많이 쓰는 신경망모델이다.
가장 기본적인 시퀀스 모델로 S2S와 깊은 연관이 있다.
**시퀀스 모델이란 입력에 순서가 있다는 말.
일반적인 Neural Network에서는 input의 순서를 다루지 못하기 때문임.
주로 번역에 기여하는 바가 많다.
**LSTM이나 GRU 또한 근본적으로 RNN기반이라고 볼 수 있다.
RNN의 구조를 그림으로 보자
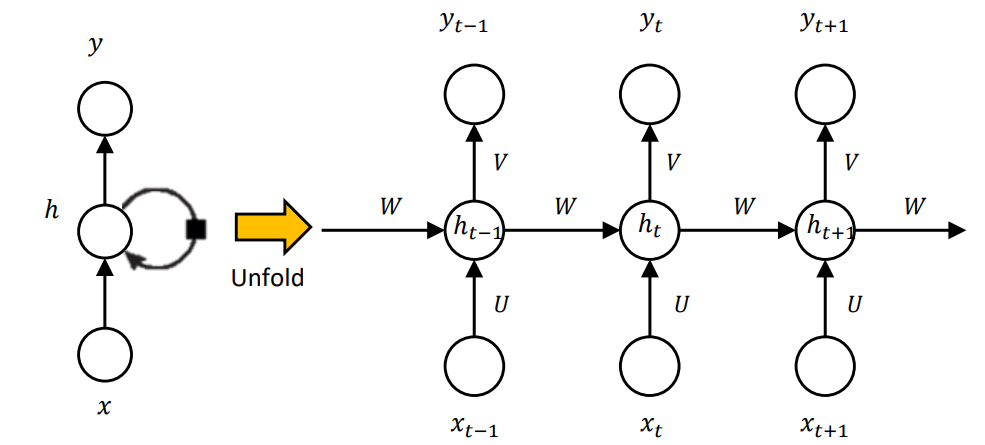
요렇게 생겼다. (좌 우 같은 그림이다)
저 A를 RNN에서는 Cell이라고 부르는데
저기에서는 각 시점(time step)에서 바로 이전 시점에서 Cell에서 계산된 값을 사용하여 지금 시점에 입력으로 사용하여 계산을 한다.
-> 이유는 Sequence Data이기 때문이다.
Xt : time step t 에서의 입력값
ht: time step t 에서의 Hidden State
다시 말하면 네트워크의 메모리로 과거의 Time step 에서 일어난 일들에 대한 정보를 담고있다.
**너무 먼 time step에서의 일에 대한 정보는 거의 없음
ht가 아래와 같이 구한다.
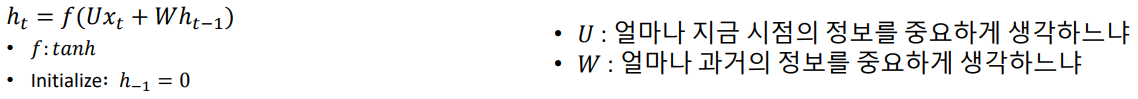
다시 표현하자면

yt : time step t 에서의 출력값
**만약 Task가 그 다음 단어 예측이라면,
𝑦𝑡는 단어 수 차원만큼의 Vector (각 단어당 할당된 확률의 집합)을 말한다.

RNN은 모든 Time step 대해 파라미터 값을 전부 공유한다.
++(U, V, W)같은 것들을 말함.
기존에는 하나의 관찰이 N개의 특징으로 정의되었으나
시퀀스 데이터에서는 t시간 동안 n 개의 특징이 이루는 2차원 배열이 된다.
다시 말하면 입력에 데이터의 길이와 현재 해당 데이터가 가지고 있는 특징 수가 들어간다.
++거기에 batch_size가 들어가서 3차원 입력이 된다.
**일반적으로 [batch_size, sequence_length, num_feature] 로 3차원 ndarray로 이루어진다.
즉, 3차원의 2가지 종류 입력이 Cell에 들어오는 것이다.
1. 현재 시점의 시퀀스 입력
2. 이전 시점에 Cell에서 계산된 값.
그렇게 나오는 것이 현재 Cell에서 계산되는 값이다.
당연히 얘는 다음 시퀀스 입력과 쓰일 다른 입력이겠다.
추상화해서 이해시켜줘!!
현재 시점(t)로 두고 RNN을 추상화한다.
t 시점에서 Cell이 갖고 있는 값은 과거의 Cell들이 계산되어 나온 값이라고 볼 수 있다.
**이전 시점의 Cell 값을 넣으니 t는 t-1 시점의 값을 넣었겠지??
우리는 값을 Value라고 하지만 우리는 다르게 정의하기로 한다.
바로 Hidden state(은닉 상태) 라는 용어로 바꿨다.
++ t =1 시점의 특징을 이용하여 t = 1에서 prediction을 한다.
t = 2 시점과 t = 1 시점의 특징을 이용하여 t = 2에서 prediction을 한다.
....
같은 방식으로
누적된 이전 시각의 정보를 이용해 다음 시각에 대해서 prediction을 한다.
Loss는 아래와 같이 구한다.

누적해서 Loss를 구한다.

결국 다시 말하면
순방향 신경망에서의 의미를 본다면
각 층의 출력은 해당 층에서 입력된 단일 관찰을 나타낸 "표현"이고
** 표현이란 각 층의 출력을 말한다
두 번째 층의 표현은 최초 특징을 조합한 특징이고
세 번째 층의 표현은 이 표현을 다시 조합한 "특징의 특징"이라고 볼 수 있다.
**순방향 계산이 끝나면 신경망에는 각 층마다 원래 관찰의 표현이 남는다.
-> 그 다음 관찰이 입력되면 해당 표현은 폐기된다.
자세히 말하자면
t = 1에서의 관찰이 입력되고 t = 1에서 prediction을 하면 각 층에 "표현" 이 남는다.
t = 2 에서 t = 1의 표현이 남은 상태에서 t = 2의 관찰이 입력된다.
새로 입력된 관찰과 남은 표현을 이용하여 t = 2를 prediction 한다.
그 후 각 층의 "표현"을 수정한다.t = 3 에서도 t = 1, t = 2 의 관찰로 결정된 "표현"이 남아있는 상태에서 t = 3의 관찰이 입력되고 "표현"으로 예측하고 다시 각 층의 "표현"을 수정한다.
....
아래와 같은 그림이다.

입력이 2개라고???
물론 위에서 입력이 2개라고 했지만 크게 보면 2가지라는 것이지 꼭 2개라는 것은 아니다.
입력과 출력의 차원이 달라지면 달라질 수 있다.

초록색이 Cell이다.
밑에가 Input, 위에가 Output이다.
다시 요약하자면
RNN이라는 Network는
시퀀스 단위, 다시 말해서 순서가 있는 데이터를 다루기 위해 만든 뉴럴 네트워크라고 보면 되겠다.
**순서는 일반적으로 시간순이 있다.
RNN의 개선

RNN의 한계점
시점에 따라 가중치를 계산해야함 실제로 멀리 떨어진 것이 중요함에도 RNN은 인식을 못할 수 있음
-> 벡터 기울기(Gradient) 소실 또는 폭발 발생 가능성 (Vanishing or Exploding)
소실의 이유: 역전파 과정에서 입력층으로 가면서 기울기 작아짐
폭발의 이유: 기울기가 커지면서 가중치도 큰 값이 되고 발산됨.
이러한 문제는 T-BPTT, LSTM으로 해결가능
(Truncated Back Propagation Through Time & Long Short-Term Memory)
->이는 부분적 Backprop 진행과 같은 기법임
[데이터 사이언스(Data Science)/딥러닝, Deep Learning, 심층학습] - LSTM, Long Shor Term Memory ; RNN 확장 신경망
참고링크들
towardsdatascience.com/understanding-rnn-and-lstm-f7cdf6dfc14e
'데이터 사이언스(Data Science) > 딥러닝, Deep Learning, 심층학습' 카테고리의 다른 글
| CNN, Covolutional Neural Network, 합성곱 신경망이란? (0) | 2021.09.23 |
|---|---|
| 신경망 기본 원리 - 합성함수 (2) | 2021.09.10 |
| LSTM, Long Shor Term Memory ; RNN 확장 신경망 (0) | 2021.01.13 |
| [DL] 퍼셉트론(Perceptron) (0) | 2020.08.20 |